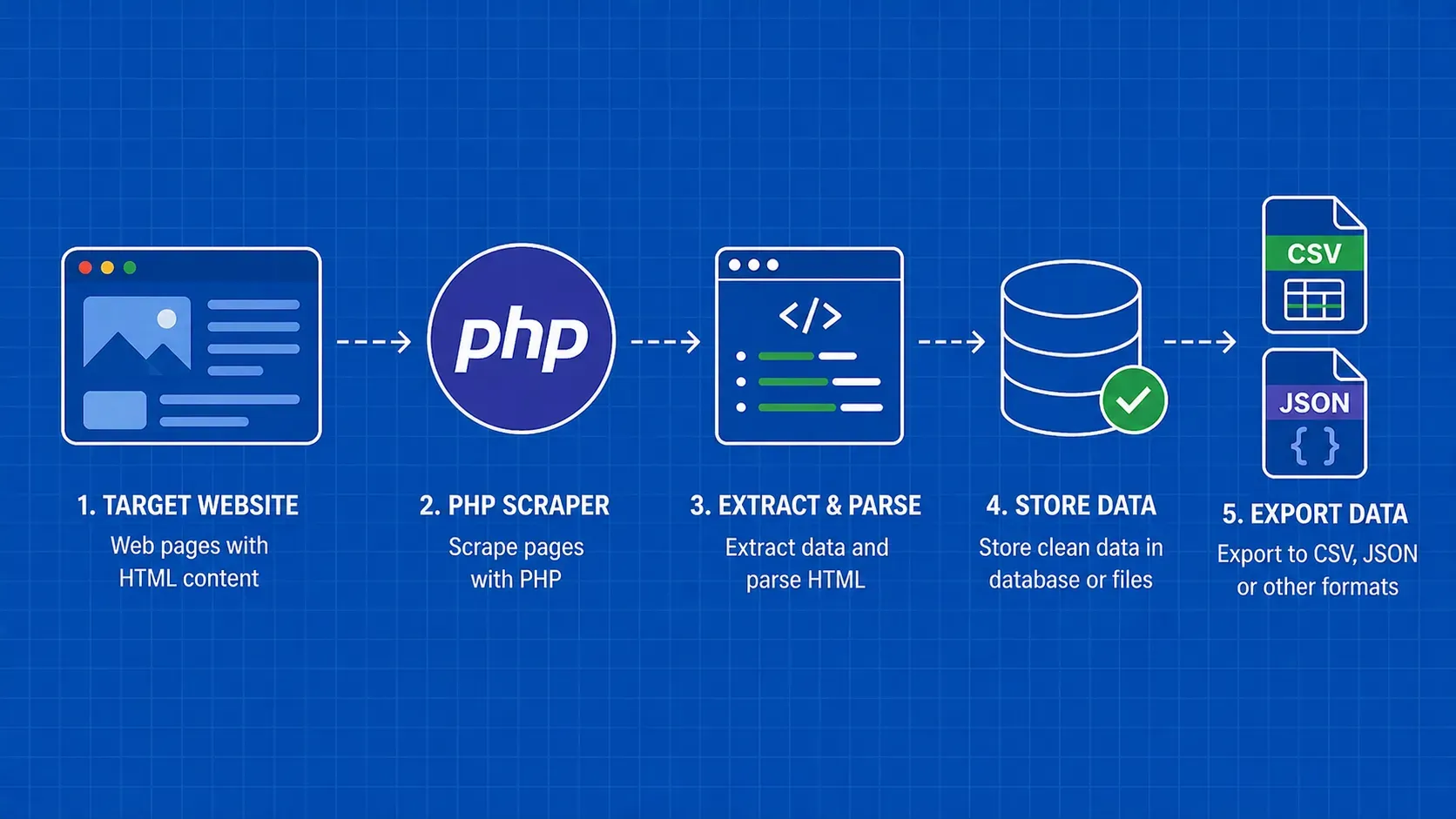
TL;DR: PHP is a perfectly capable language for web scraping, thanks to built-in extensions like cURL and DOMDocument, plus a rich Composer ecosystem that includes Guzzle, Symfony DomCrawler, and Symfony Panther for headless browsing. This guide walks you through the full workflow: fetching pages, parsing HTML, storing results in CSV/JSON/MySQL, handling errors, and avoiding blocks.
Web scraping with PHP is the process of programmatically fetching web pages and extracting structured data from their HTML using PHP scripts and libraries. If you already write PHP for your day job, there is no reason to switch languages just to pull data from websites. PHP ships with cURL bindings and a built-in DOM parser out of the box, and Composer gives you access to battle-tested HTTP clients, CSS-selector engines, and even headless browsers.
This tutorial is aimed at intermediate PHP developers who want a practical, code-first walkthrough. You will start with low-level cURL calls, graduate to higher-level libraries like Guzzle and Symfony HttpBrowser, tackle JavaScript-rendered pages with Symfony Panther, and finish with production concerns like data storage, error handling, and staying off blocklists. Every example in this PHP web scraping tutorial threads through a single scenario (scraping a public book-listing site) so you can follow the full workflow end to end rather than jumping between disconnected snippets.