Science of Web Scraping
HTTP Response Headers in cURL: Every Flag, Technique, and Scripting Recipe
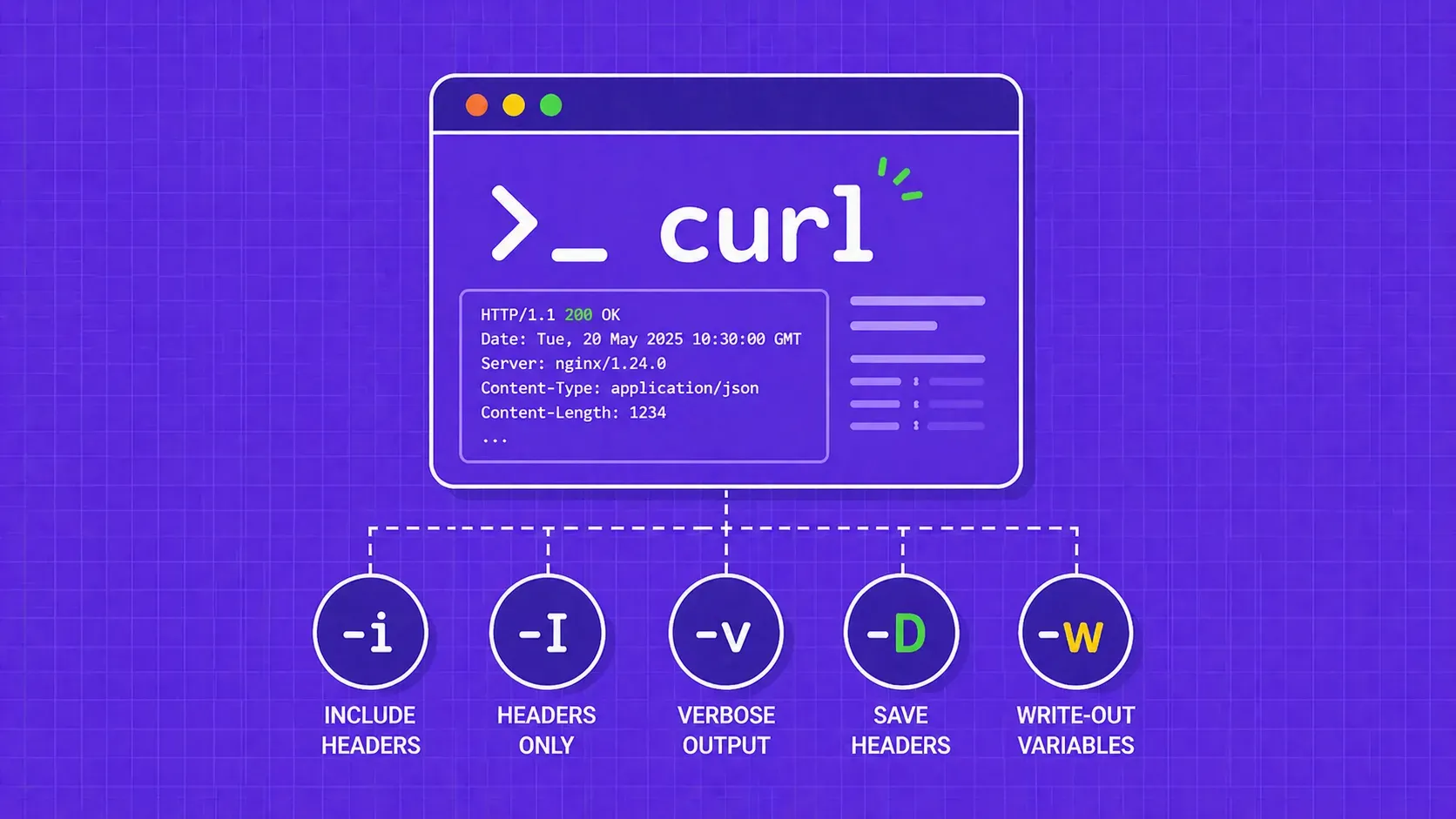
TL;DR: cURL hides response headers by default. Use -i to see headers alongside the body, -I for a HEAD request that returns headers only, -v for full request/response debugging, and -D to save headers to a file. For modern scripting, cURL 7.83+ lets you extract individual headers or dump all of them as JSON with the -w write-out option.
Suciu Dan11 min read
Apr 29, 2026