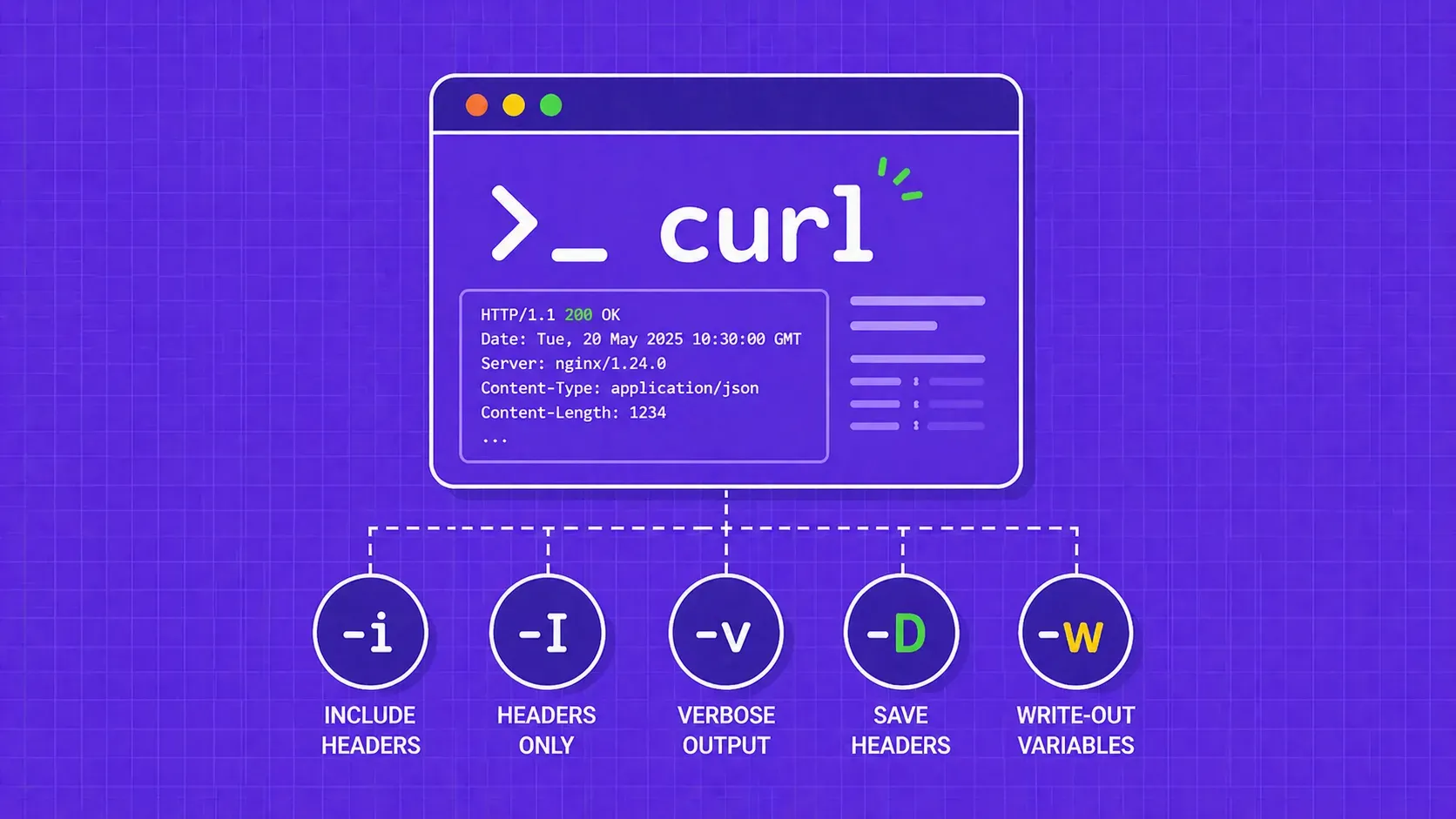
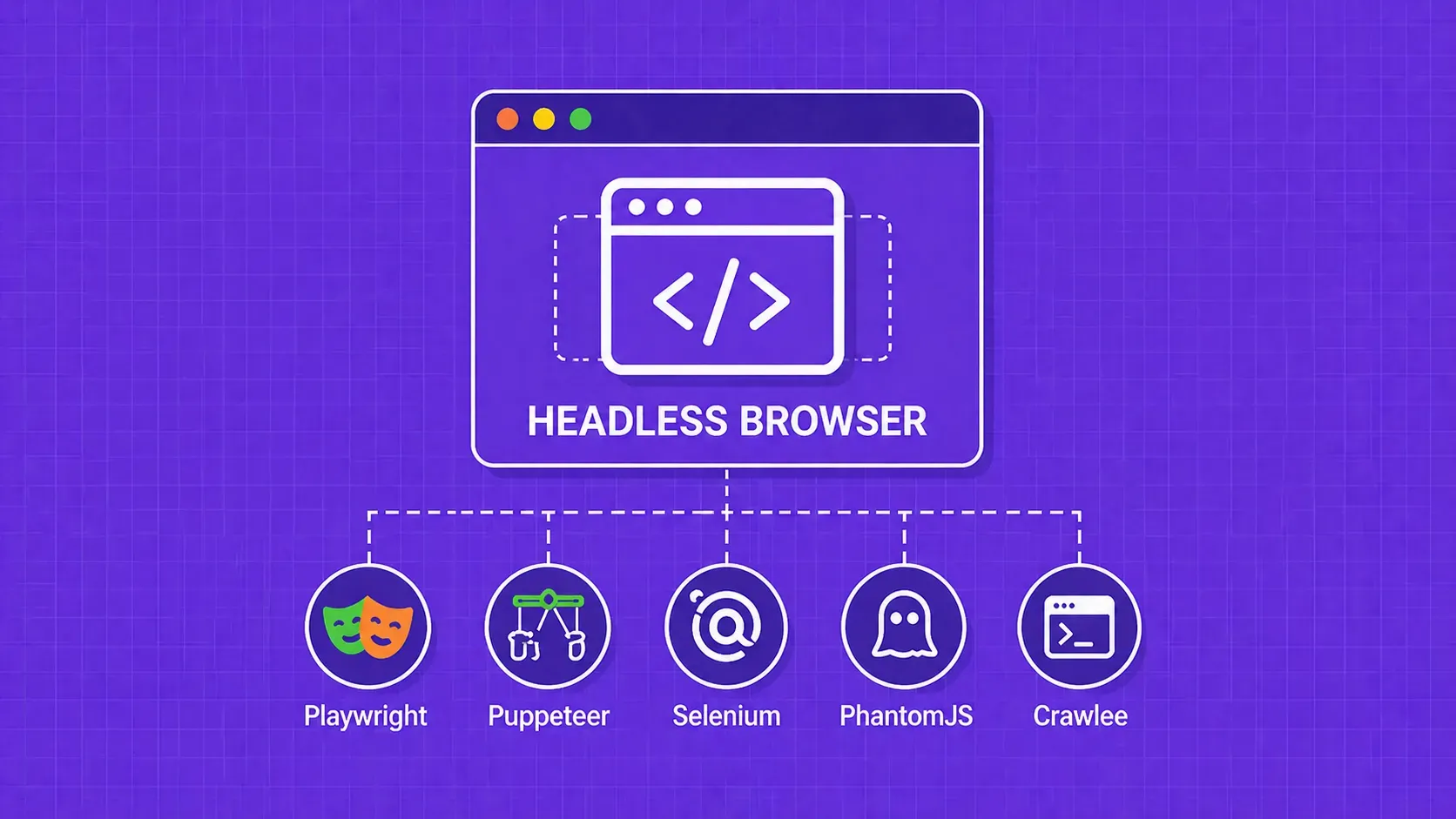
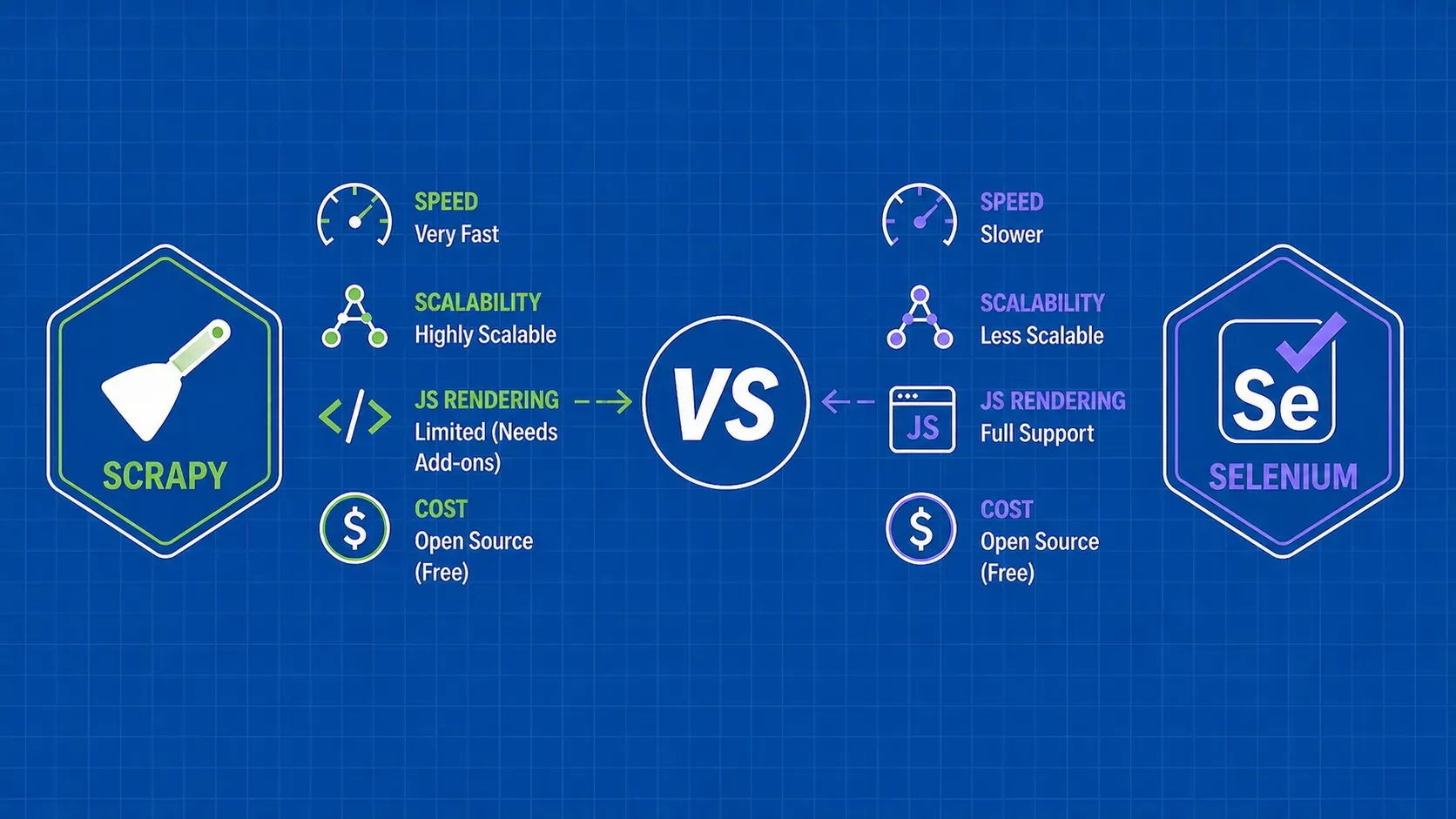
While web scraping can sound easy in practice, there are plenty of pitfalls that the uninitiated developer could run into. Instead of brute-forcing it until you run out of unbanned proxies, I dare to think that it’d be better to scrape smart, get the data you need and get out without ever being noticed.
The real question is how to do that? How does one get information without getting IP-blocked, running into CAPTCHAs, retrieving useless JavaScript code, and tweaking the scraper’s code endlessly? Well, there isn’t one golden rule to follow, but there are best practices.
We've prepared twelve tips for you. Use them and you'll see that all the Internet's data is just a few clicks away.