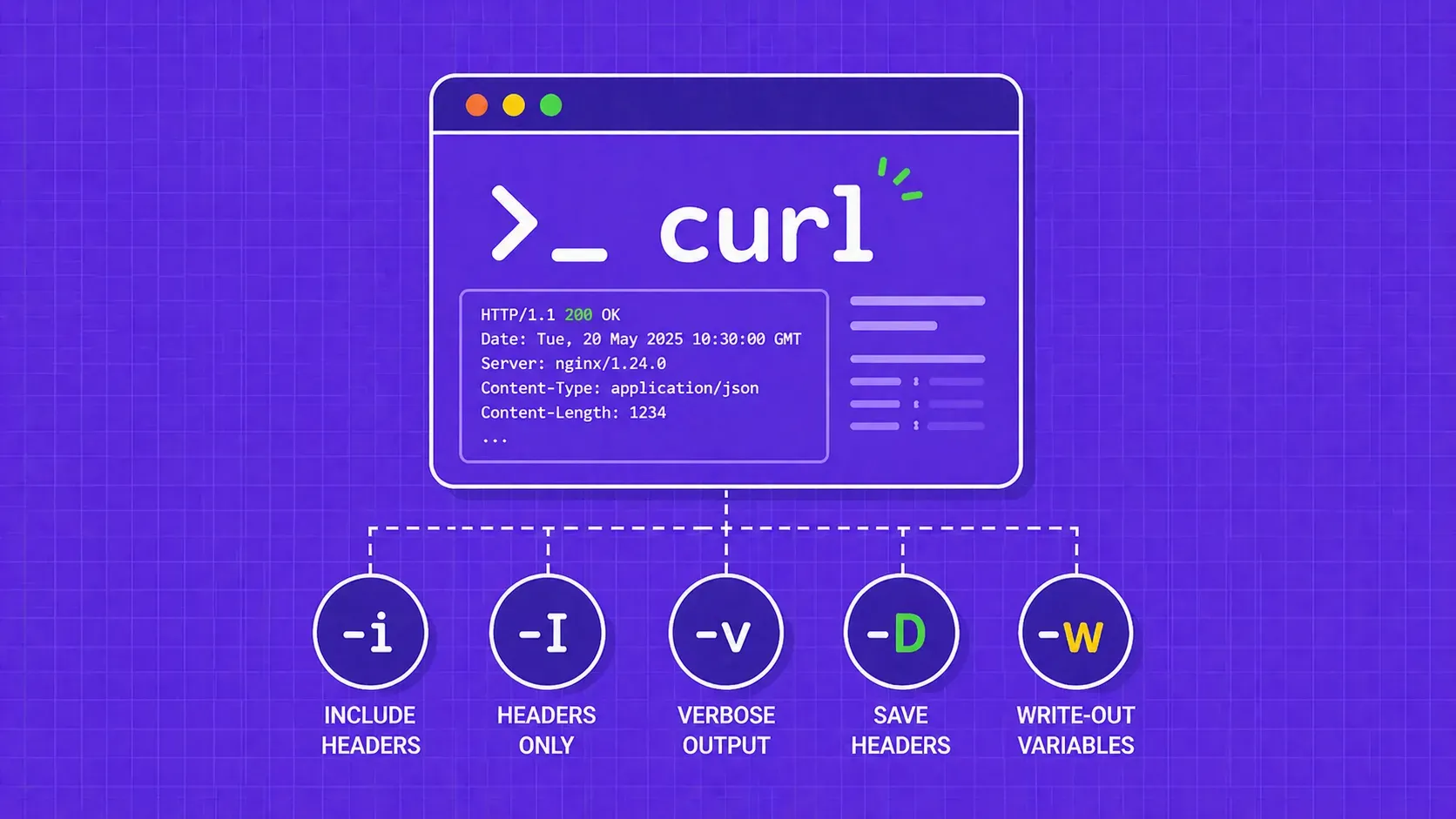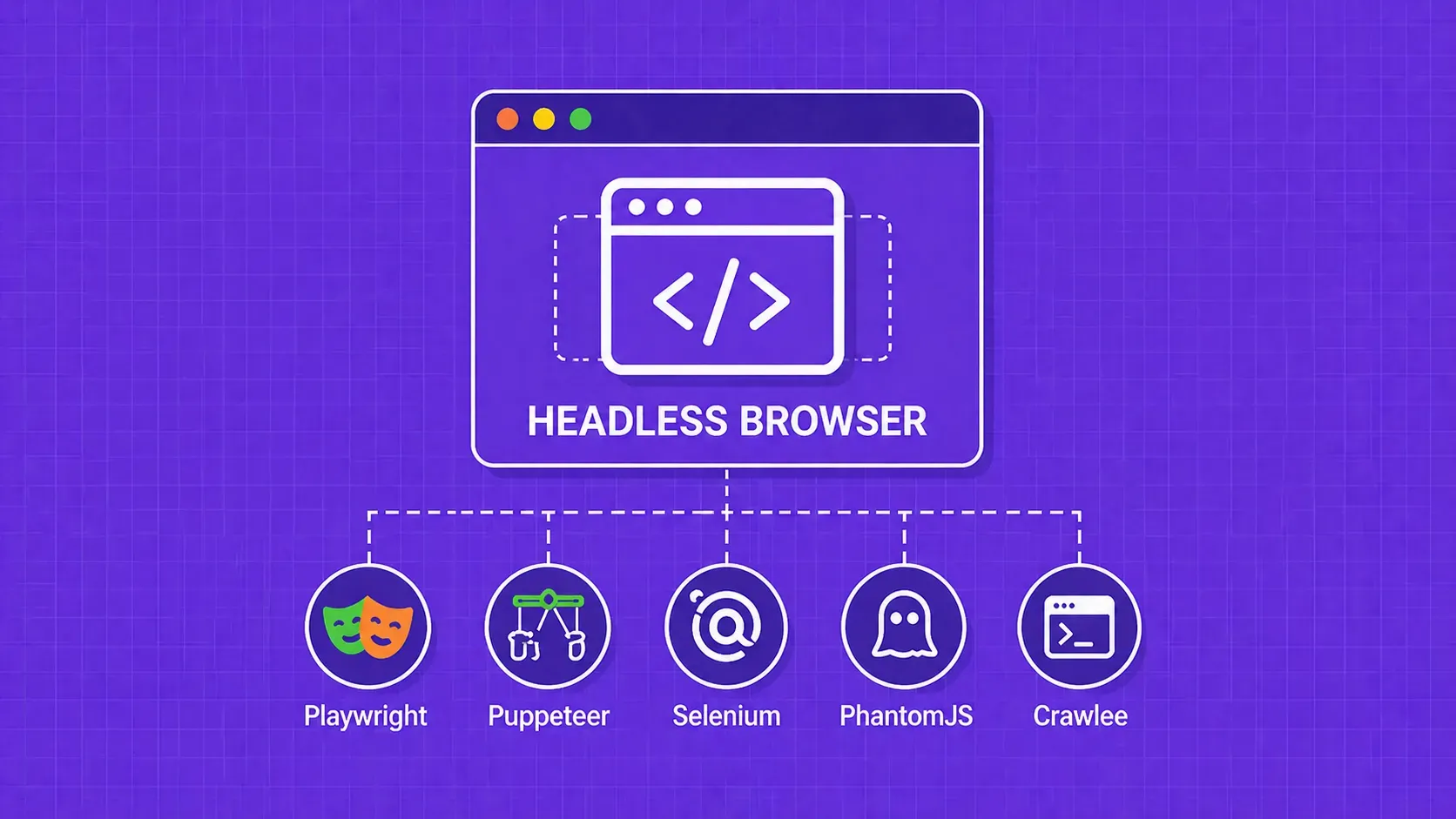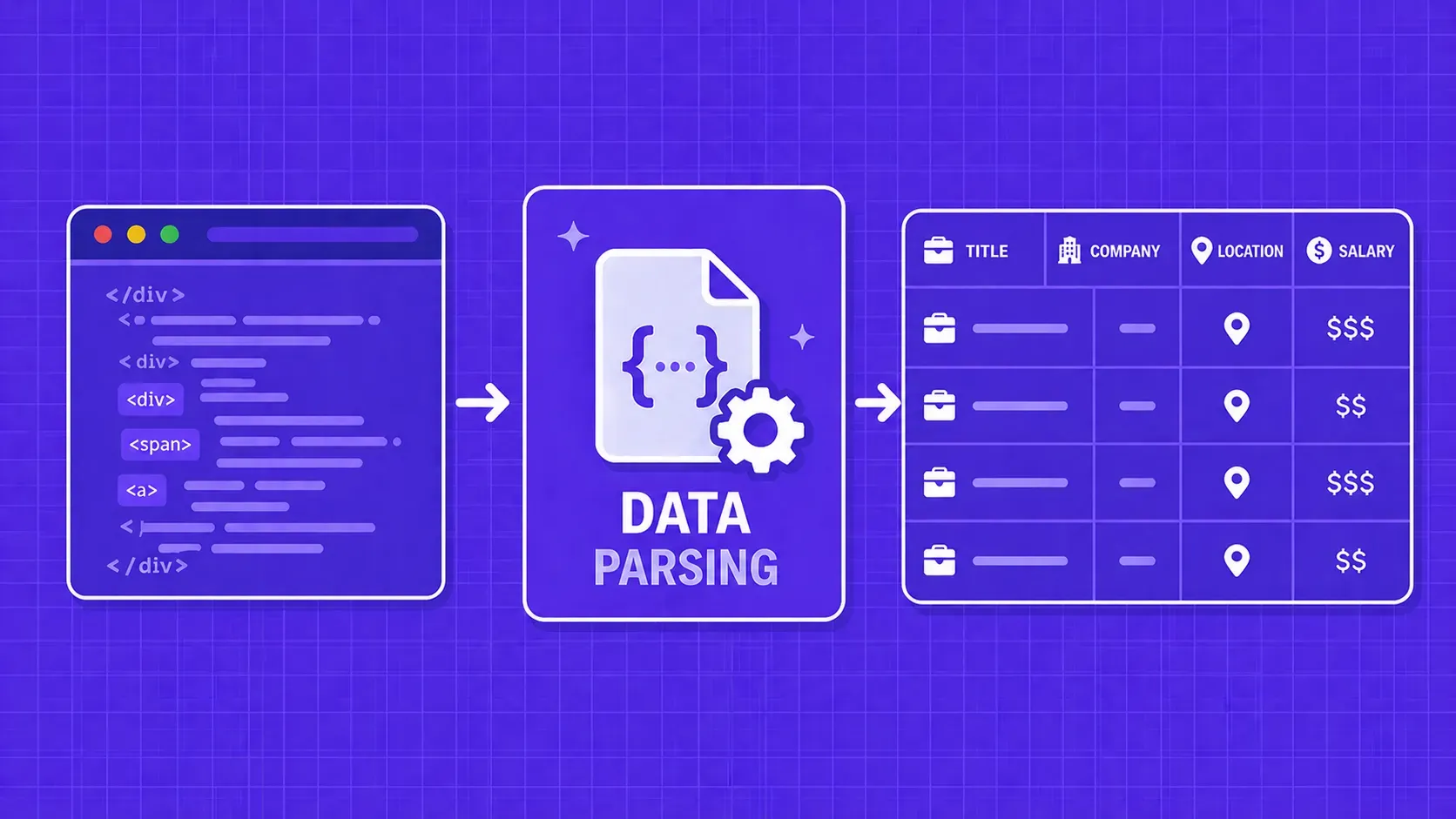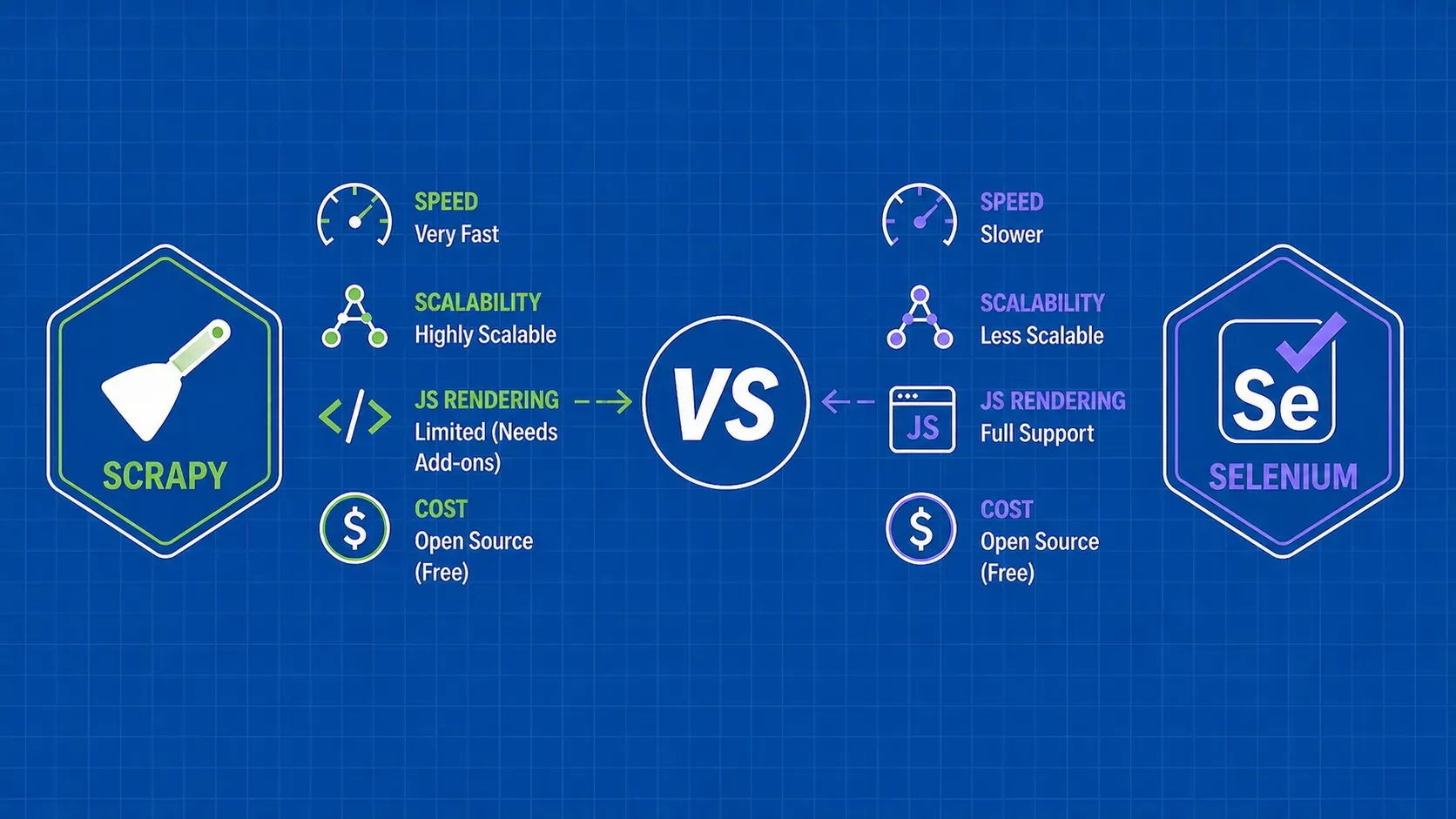
TL;DR: Scrapy is a high-speed, asynchronous crawling framework built for extracting structured data from static pages at scale. Selenium automates real browsers and handles JavaScript-heavy sites, but at a much higher resource cost. Most production scraping projects benefit from knowing when to use each, or when to combine them.
When two tools dominate the web scraping conversation, the natural question is: which one should I actually use? The scrapy vs selenium debate comes up constantly among Python developers, and for good reason. These frameworks solve overlapping problems with fundamentally different architectures. Scrapy is a purpose-built crawling engine designed for speed and structured data extraction. Selenium is a browser automation tool that happens to be great for scraping JavaScript-rendered pages. This guide breaks down the real differences across performance, features, scalability, and total cost of ownership so you can make a confident decision for your next project.