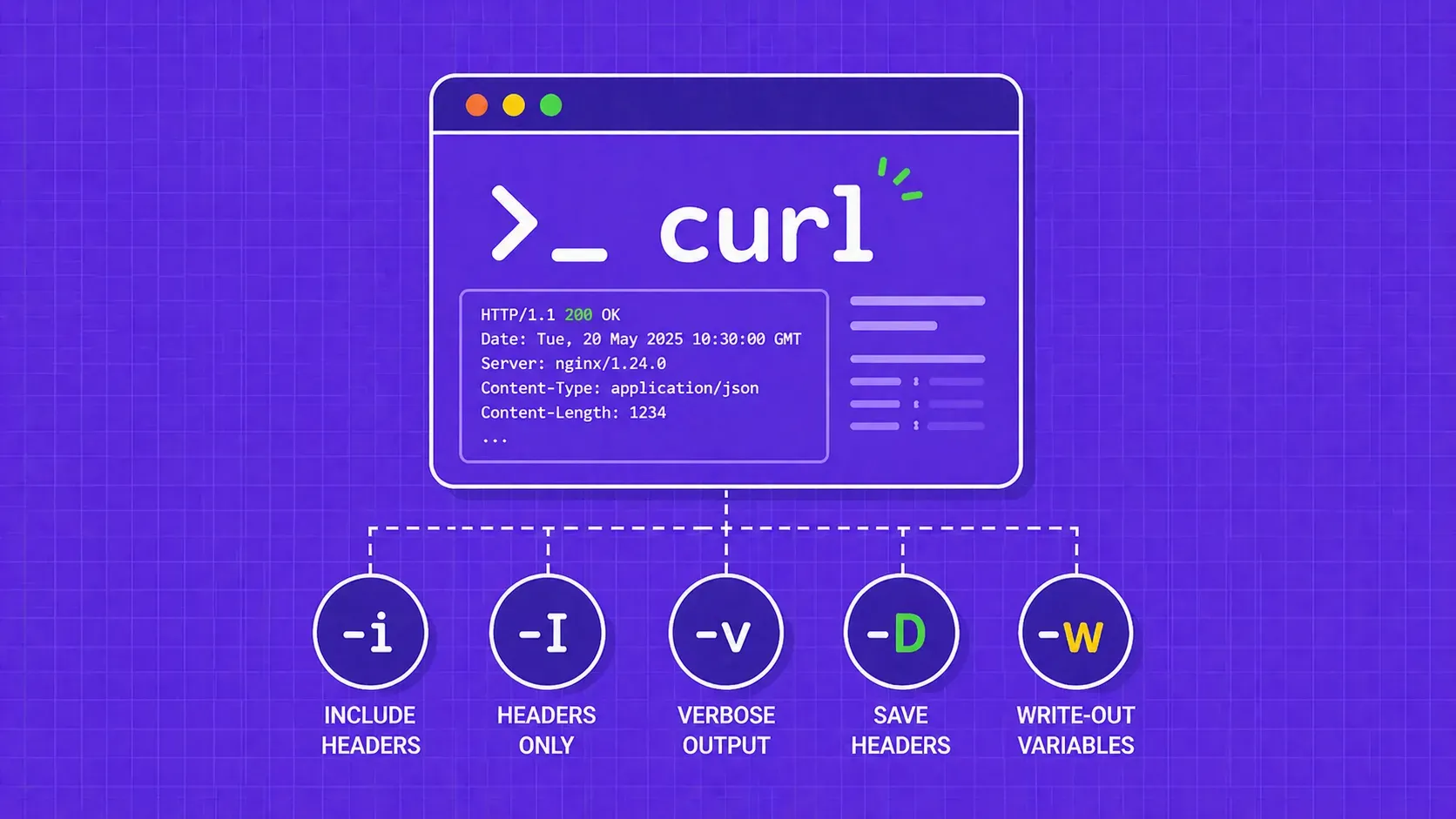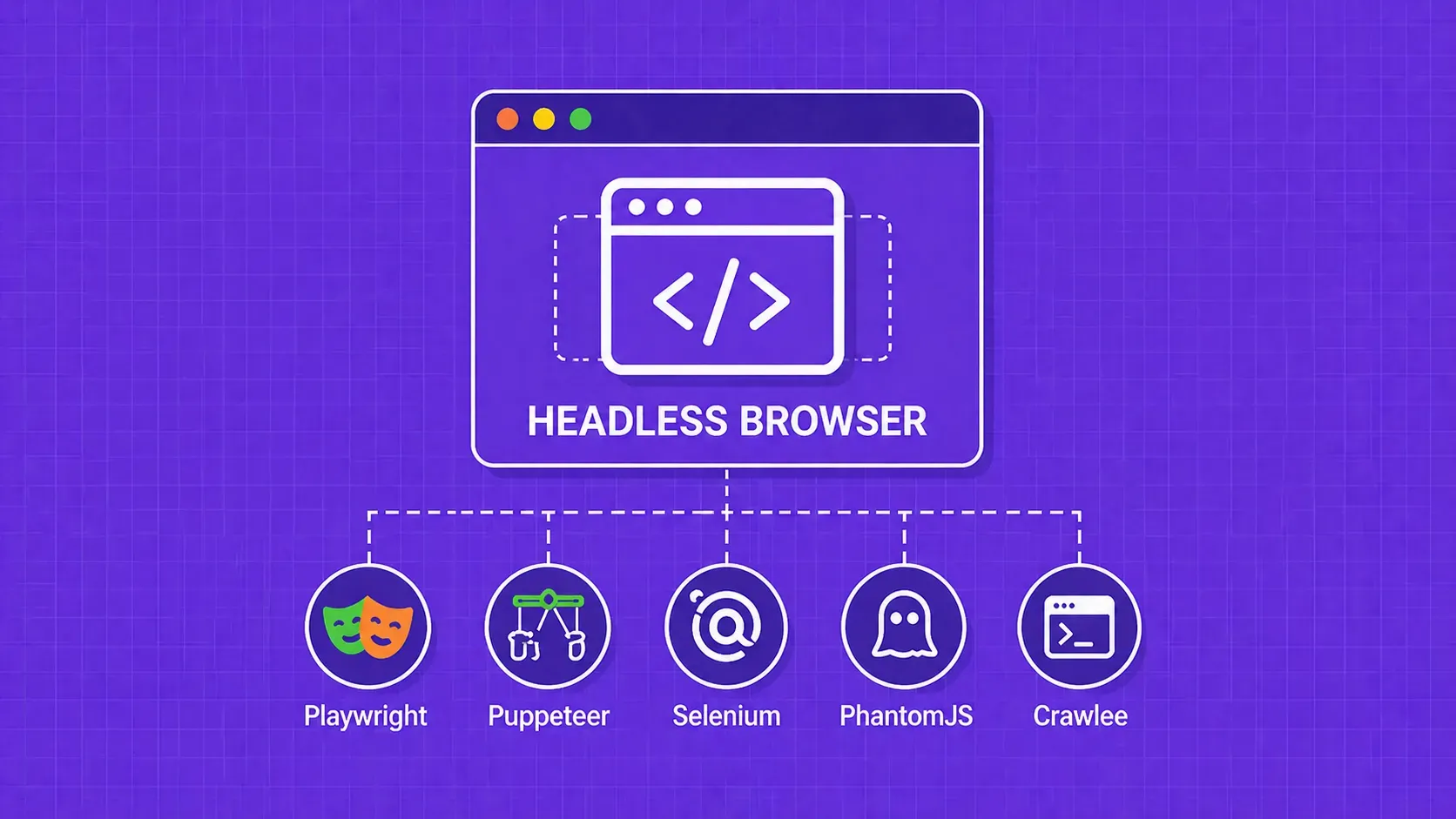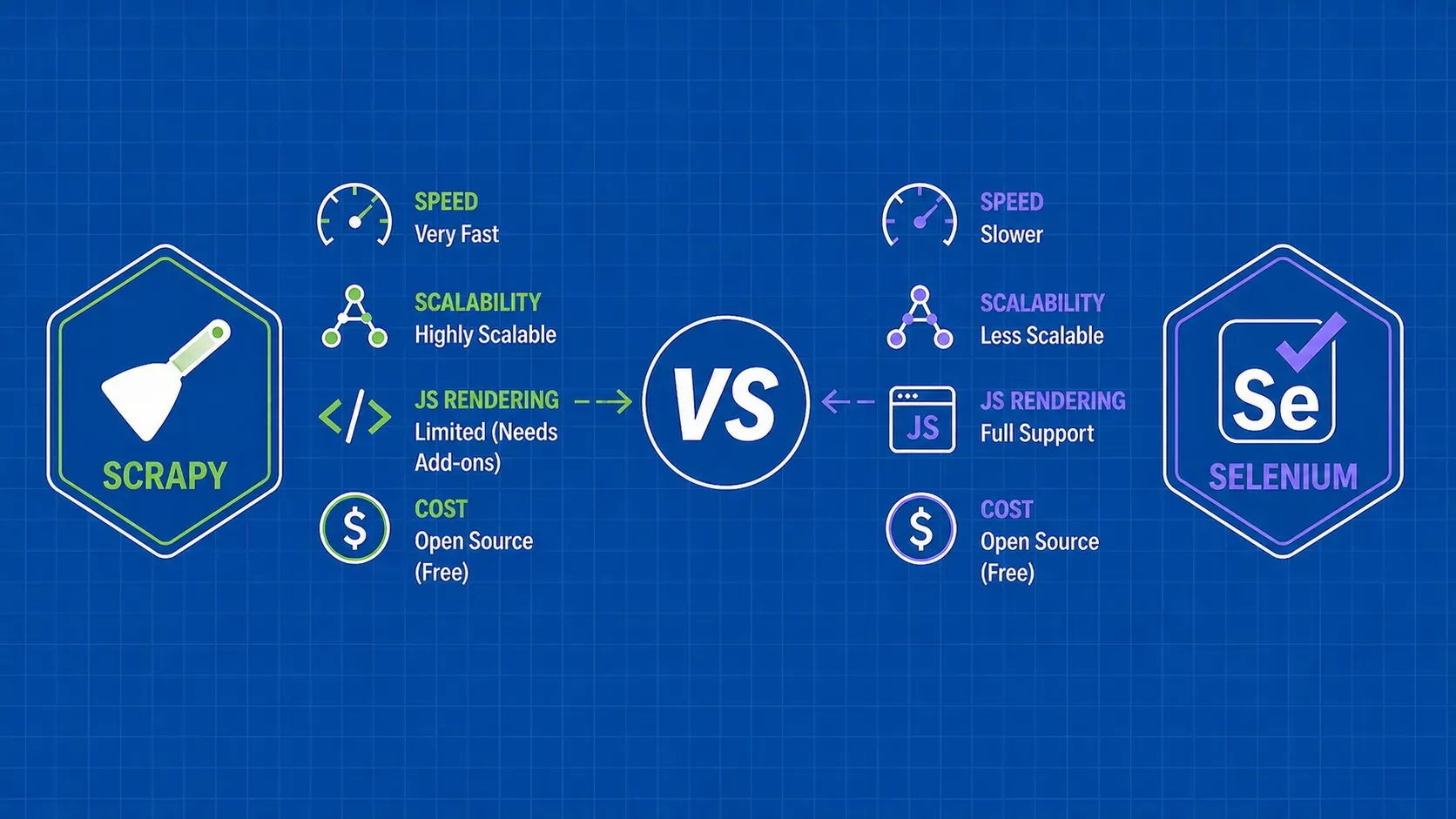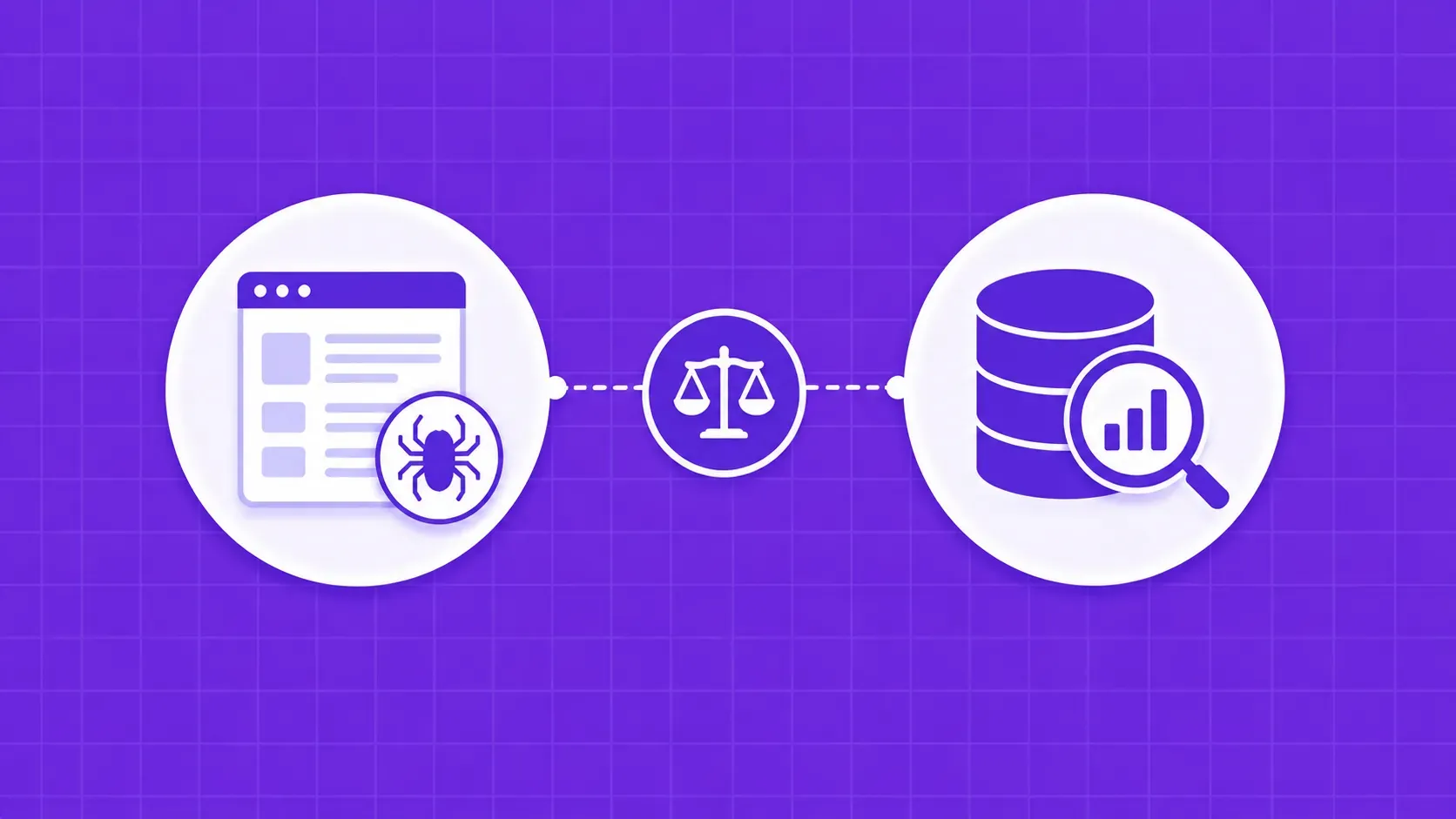
TL;DR: Web scraping collects raw data from public web pages. Data mining analyzes structured data to surface patterns, predictions, and segments. They are different stages of the same lifecycle, and most production systems combine them in a scrape-then-normalize-then-mine pipeline.
If you have ever sat in a planning meeting where someone said "we need to do data mining on the competitor data" and someone else heard "we need to scrape the competitor data," you have already seen the cost of mixing up web scraping vs data mining. The two terms get used interchangeably so often that they cause real scoping mistakes: wrong tools picked, wrong owners assigned, wrong success metrics agreed.
Web scraping vs data mining is one of the most persistent confusions in the data space, and the cleanest way to settle it is to look at what each one actually does, end to end. This guide covers the working definitions, the pipelines behind each, the tools that barely overlap, the legal limits that apply differently to collection and to analysis, and a five-question decision check you can run in under a minute. The audience is practitioners scoping a real project, not students writing a glossary entry.