XPath Vs CSS Selectors
Mihai Maxim on Apr 25 2023

XPath vs CSS
As a web scraping enthusiast, you've probably come across the terms XPath and CSS selectors. These are two popular ways to navigate and extract elements from an HTML or XML document, but what exactly are they and how do they differ? In this article, I'll take you through a side-by-side comparison of XPath and CSS selectors, discussing their features and use cases.
We'll start with a brief overview of XPath and CSS selectors, and use examples to show how they can be used to navigate and extract elements from an HTML document. We'll explore the differences in syntax and capabilities, and look at the various built-in functions that XPath offers, and how to achieve the same results using CSS and JavaScript. We'll also discuss the pros and cons of each method and how to decide which one to use for your project.
So, grab a notebook, sharpen your pencil, and get ready to dive into the world of XPath and CSS selectors!
Selectors overview
XPath, short for XML Path Language, is a query language that is used to navigate through an XML document. It was first introduced in 1999 as a way to provide a standard way to access elements within an XML document. The language is built around the concept of a "path" which is used to select specific elements based on their position within the document.
One of the key features of XPath is its use of path notation. This notation allows you to select elements based on their location in the document tree. For example, in an HTML document, the path "html/body/p" would select all p elements that are direct children of the body element, which in turn is a direct child of the html element.
The syntax for XPath is pretty straightforward:
//tagname[@attribute='value']
Where 'tagname' is the type of HTML element you are looking for (e.g. div, a, p), 'attribute' is a property of the desired HTML element by which our locator performs the search (e.g. class) and 'value' is the specific value you want to match
CSS selectors, short for Cascading Style Sheets, are used to select elements based on their properties, such as class, id, and attributes. They are easier to read and understand than XPath, but they are limited in their ability to navigate through the document. CSS selectors are mostly used for styling and layout, but you can also use them to extract information from a webpage:
<html> <body> <p class="highlight">Hello, world!</p> </body> </html>
|
To select the text "Hello, world!" using CSS selectors, we’ll have to use Javascript:
let p_tag = document.querySelector(“p.highlight”)
let p_text = p_tag.innerText
XPath on the other hand, was specifically designed to provide a query language for XML documents and comes with a wide range of built-in functions. These functions can be used to perform calculations and extract specific information from the elements. For example, with XPath's text() function, you can directly select the text value of an element:
<html> <body> <p>Hello, world!</p> </body> </html>
To select the text "Hello, world!" using the text() function in XPath, the expression would be:
/html/body/p/text()
Additional resources
If you're looking to delve deeper into the world of XPath and CSS selectors, we have a couple of articles that can help. This first article covers the basics of XPath selectors, including the syntax, functions, and how to navigate the DOM tree. This second article delves into the basics of CSS selectors, including the different types of selectors.
Setting up an example
In order to clearly illustrate the main differences between XPath and CSS selectors, let’s analyze a mock HTML structure:
<!doctype html>
<html>
<head>
<title>Top News</title>
<meta charset="utf-8" />
</head>
<body>
<h1>Top News Stories</h1>
<div class="container">
<div class="news-story">
<h2> <a href="https://edition.cnn.com/2022/12/28/weather/buffalo-winter-storm-new-york-blizzard-wednesday/index.html">Winter Storm</a> </h2>
<p>Winter storm death toll rises to 37 in Buffalo as criticism arises over handling of storm and cleanup</p>
</div>
<div class="news-story">
<h2> <a href="https://www.nbcnews.com/politics/politics-news/spacex-leader-reassured-nasa-chief-elson-musk-rcna61189">SpaceX</a> </h2>
<p>NASA chief: SpaceX leader says Elon Musk’s Twitter drama is ‘nothing to worry about’.</p>
</div>
</div>
</body>
</html>
Testing the selectors in the Developer Tools
Testing XPath and CSS selectors in the developer tools is a quick and easy way to verify that your selectors are working correctly. The process is similar in most modern browsers, but for the purpose of this example, we will be using Google Chrome.
To start, open the webpage that you want to test your selectors on in Google Chrome. Next, right-click on an element that you want to select and choose "Inspect" from the context menu. This will open the developer tools window:
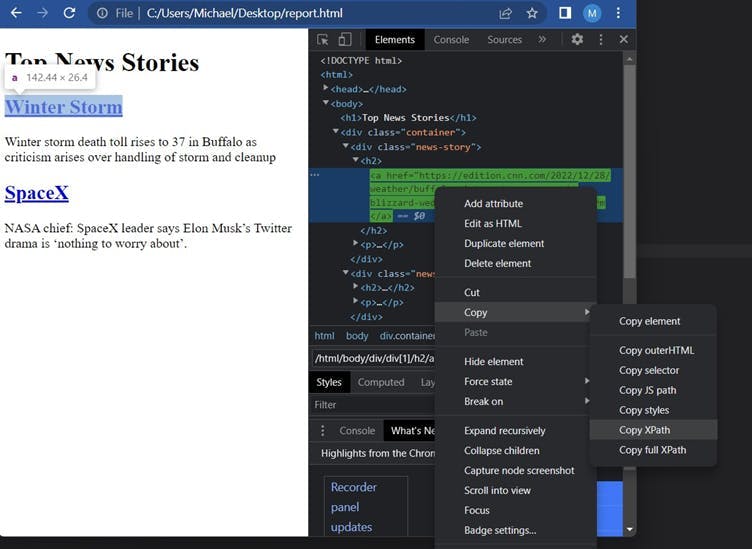
In the developer tools window, you will see the HTML source code of the webpage on the left side and the corresponding rendered webpage on the right side.
To find the full XPath and CSS selector of an element, right-click the element in the HTML and select "Copy > Copy full XPath" or "Copy > Copy selector." This will copy the complete path to the element, including all parent elements, to your clipboard. You can then paste this path into your code or into the developer tools search bar (ctrl+f) to access the element.
For example, if you wanted to select all the h2 tags from the example html provided above, you would type "//h2" in the search bar and press enter.
The main takeaways
One of the main differences between XPath and CSS is that XPath can select elements based on their position in the document. CSS selectors are limited to selecting elements based on their properties.
For example, in XPath, we can select the second div element with the class news-story by using the expression //div[@class='news-story'][2]. With CSS selectors, we can only select it using div.news-story:nth-child(2).
div.news-story:nth-child(2) will select the second div element among all the div elements that have the class “news-story” and are children of the same container element.
//div[@class='news-story'][2] allows you to select the element based on its position in the entire document. The element does not have to be the child of a specific container element:
<html>
<body>
<div class="container">
<div class="news-story">
<h2>News Story 1</h2>
</div>
</div>
<div class="container">
<div class="news-story">
<h2>News Story 2</h2>
</div>
</div>
</body>
</html>
For this specific example, div[@class='news-story'][2] selects the second story.
div.news-story:nth-child(2) does not select anything since every container element has only one direct child.
Greater flexibility
XPath allows for greater flexibility in navigating the DOM tree. It includes the ability to move up and down the tree. CSS selectors only allow for navigation downwards. This makes XPath more powerful and versatile, but also more complex.
With XPath, you can use axes such as the parent and ancestor axes to access the parent or ancestor of an element, which is not possible with CSS selectors.
For example, the XPath expression //div[@class='news-story'][1]/parent::*//h2 selects the first div element with class "news-story". It then navigates to its parent element using the parent::* operator, and then selects the h2 element within that parent element.
Alternatively, you can use square brackets to select the parent element of the first div element with class "news-story" and then select the h2 element within that parent element using //div[@class='news-story'][1]/..//h2.
Built in functions
Another important difference between XPath and CSS selectors is that XPath has a wide range of built-in functions, such as count(), sum(), string(), substring(), and contains(). These functions can be used to manipulate elements and extract data.
count() can be used to count the number of elements that match certain criteria. For example, to count the number of div elements with the class news-story, we can use the XPath expression count(//div[@class='news-story']).
The CSS and JavaScript counterpart would be:
document.querySelectorAll('div.news-story').lengthsum() can be used to calculate the sum of a certain value for a set of elements that match certain criteria. For example, to calculate the total number of characters in the text content of all the p elements, we can use the XPath expression sum(//p/text()/string-length()).
The CSS and JavaScript counterparts would be:
var sum = 0;
var elements = document.querySelectorAll('p');
elements.forEach(function(element) {
sum += element.innerText.length;
});
console.log(sum);
substring() can be used to extract a substring from a string. For example, to extract the second to the fifth character of the text content of a certain element, we can use the XPath expression substring(//p/text(), 2, 5).
The CSS and JavaScript counterparts:
document.querySelector('p').innerText.substring(2, 5)contains() can be used to check whether a string contains a certain substring. For example, to check whether the text content of a certain p element contains the word "Winter", we can use the XPath expression //p[contains(text(),"Winter")]
Advantages of CSS selectors
CSS selectors have several benefits over XPath that make them a great choice for certain projects. One of the main benefits of CSS selectors is their simplicity and readability. Unlike XPath, which can be complex and difficult to read, CSS selectors are easy to understand and use.
Another benefit of CSS selectors is their performance. Because CSS selectors only navigate down the DOM tree, they are generally faster than XPath, which can navigate up and down the tree.
Finally, CSS selectors are also more widely used in web development. This means that web developers are more likely to be familiar with them and may be more willing to help you with your projects.
Wrapping up
In summary, XPath and CSS selectors are both powerful tools that allow you to navigate and extract elements from an HTML document. XPath is powerful and flexible but can be difficult to read, while CSS selectors are easier to read but are limited in their ability to navigate through the document.
When choosing between XPath and CSS selectors, consider the structure of the document and the information you want to extract. If you are looking to extract data based on the position of elements, XPath is the better choice. However, if you are looking to extract data based on properties such as class or id, CSS selectors are a better option.
If you're interested in learning more about how web scraping can help your business, I invite you to reach out to us at WebScrapingAPI. We are more than happy to answer all your questions!
News and updates
Stay up-to-date with the latest web scraping guides and news by subscribing to our newsletter.
We care about the protection of your data. Read our Privacy Policy.

Related articles

Explore the transformative power of web scraping in the finance sector. From product data to sentiment analysis, this guide offers insights into the various types of web data available for investment decisions.


Dive into the transformative role of financial data in business decision-making. Understand traditional financial data and the emerging significance of alternative data.


Discover how to efficiently extract and organize data for web scraping and data analysis through data parsing, HTML parsing libraries, and schema.org meta data.