Learn How To Bypass Cloudflare Detection With The Best Selenium Browser
Mihnea-Octavian Manolache on May 02 2023

Nowadays, web scraping has become a really challenging task. If you ever built a web scraper with a headless browser, most definitely you came across some anti-bot systems. And bypassing cloudflare, datadome, or any other anti-bot provider for that matter, is no easy task. You have to first think of evasion strategies and then implement them in production. And even so, there might be scenarios that you never accounted for.
Yet without at least a minimal implementation of these evasion techniques, your chances of getting caught and blocked are very high. That is why, the topic for today’s article is how to bypass cloudflare detection. And most of the techniques we’re going to discuss apply to other detection vendors as well. As a reference, we’ll focus on Selenium to see if we can make it stealthy. Throughout the article, among others, I’ll discuss:
- Bot detection methods
- General anti-bot evasion techniques
- Advanced evasions for Selenium
How does Cloudflare detect headless browsers?
Cloudflare is a tech company with a giant network. They focus on services like CDN, DNS, and various online security systems. Their Web Application Firewall is usually designed to protect against attacks such as DDoS or cross site scripting. In recent years, Cloudflare added and other providers in the field introduced fingerprinting systems, capable of detecting headless browsers. As you might guess, one of the first affected by these techniques is Selenium. And since the web scraping industry relies heavily on this technology, scrapers are directly affected as well.
Before moving forward to anti-bot techniques, I think it is important to discuss how cloudflare detects Selenium. Well, the system can be very complex. For example, there are properties in a browser that a web driver lacks. The `navigator` interface in a browser even has a property called `webdriver` that indicates if a browser is controlled by automation. And that is an instant giveaway. If you want to experiment with it:
- Open your browser’s developer tools
- Navigate to the console
- Type the following command: `navigator.webdriver`
In your case, it should return `false`. But if you try it with Puppeteer or Selenium, you will get `true`. If you’re wondering how Cloudflare leverages this to detect bots, well it’s pretty simple. All they need to do is inject a script like the one below on their partner's website:
// detection-script.js
const webdriver = navigator.webdriver
// If webdriver returns true, display a reCaptcha
// In this example, I am transferring the user to a Cloudflare challenge page.
// But you get the idea
if ( webdriver ) location.replace('https://cloudflarechallenge.com')
Of course, in real life, there are many more levels of detection these providers use. Even the size of the screen, the keyboard layout, or the plugins used by the browsers are used to specifically fingerprint a browser. If you’re interested in how browserless detection works, check out my simple service worker test. And that is just if you stick to the browser. You can also detect bot activity by looking into the IP address from where the request originates. For example, if you’re using datacenter IPs, your chances of getting blocked increase with every request. That is why it’s recommended to use residential or ISP proxies when you’re building a web scraper.
How to bypass Cloudflare with Selenium
Fortunately, the web scraping community is really active. And because there is such demand to bypass Cloudflare and other anti-bot providers, there are open source solutions in that area. Great things can be achieved when programming communities work together! Moving forward, I suggest we follow these steps:
- Run some tests to see if default Selenium can bypass Cloudflare
- Add some extra evasions to make our scripts stealthier
So let’s get started with our first step:
#1: Can default Selenium bypass Cloudflare?
I am not the type to make assumptions. And that’s especially because we don’t know for sure how Cloudflare systems work. They use all sorts of obfuscation with their code, which makes it harder to reverse engineer. That’s why, throughout my experience as a developer, I learned that testing is the best way to understand how a system works. So let us build a basic scraper and see how it behaves on a real target, protected by Cloudflare.
1.1. Set up the environment
With Python, it’s best we isolate our projects inside one single directory. So let’s create a new folder, open a terminal window and navigate to it:
# Create a new virtual environment and activate it
~ » python3 -m venv env && source env/bin/activate
# Install dependencies
~ » python3 -m pip install selenium
# Create a new .py file and open the project inside your IDE
~ » touch app.py && code .
1.2. Build a simple web scraper with Selenium
Now that you have successfully set up your project, it’s time to add some code. We’re not going to build anything fancy here. We just need this script for testing purposes. If you want to learn about advanced scraping, check out this [LINK] tutorial on Pyppeteer.
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
# Set Chrome to open in headless mode
options = Options()
options.headless = True
# Create a new Chrome instance and navigate to target
driver = webdriver.Chrome(options=options)
driver.get('https://www.snipesusa.com/')
# Give it some time to load
time.sleep(10)
# Take screenshot of page
driver.get_screenshot_as_file('screenshot.png')
# Close browser
driver.quit()
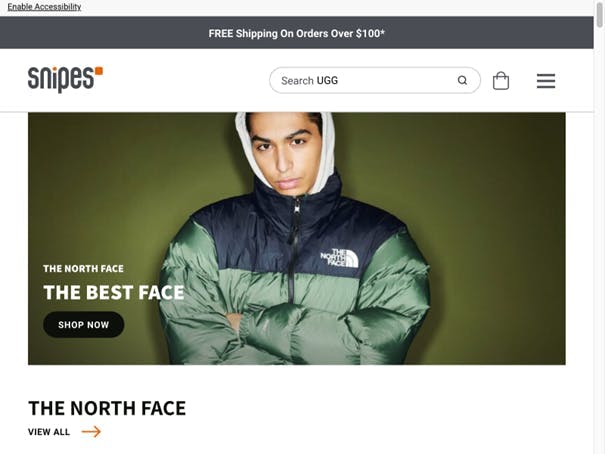
Now check out the screenshot. Here’s what I got:

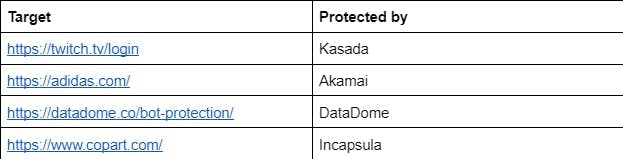
I think we’re safe to conclude that the test failed. The targeted website is protected by Cloudflare and as you can see, we’re getting blocked. So by default, Selenium is not able to bypass Cloudflare. I am not going to go in depth and check with other bot detection providers. If you want to test further, here are some targets and their vendors:
#2: Can stealthy selenium bypass Cloudflare?
First of all, let me clarify the terms. By stealth Selenium I mean a version of Selenium that can go undetected and bypass Cloudflare. I am not referring to any specific stealthiness technique. There are a couple of ways you can implement evasion techniques into Selenium. There are packages that handle it, or you can use the `execute_cdp_cmd` to interact directly with the Chrome API. The latter allows you more control but requires more work. Here is an example of how you could use it to change the user agent’s value:
driver.execute_cdp_cmd('Emulation.setUserAgentOverride', {
"userAgent": "Mozilla/5.0 (Windows NT 10.0; Win32; x86) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36",
"platform": "Win32",
"acceptLanguage":"ro-RO"
})But you’d have to go through CDP and identify the APIs that allow you to make all the necessary changes. So for the time being, let’s test with some packages.
1.1. Stealthy Selenium
There are at least two packages you can use to make Selenium stealthy. Up to this point though, none of them is guaranteed to bypass Cloudflare. Yet again, we need to test and see if either of them works. First of all, let’s look into `selenium-stealth`. This package is a wrapper around `puppeteer-extra-plugin-stealth`, making it possible to use Puppeteer’s evasions with Python’s Selenium. To use it, you have to install it first. Open a terminal window and enter this command:
# Install selenium-stealth
~ » python3 -m pip install selenium-stealth
You’re all set now. We can use it to make our previous scraper stealthier:
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium_stealth import stealth
import time
# Set Chrome to open in headless mode
options = Options()
options.headless = True
# Create a new Chrome instance
driver = webdriver.Chrome(options=options)
# Apply stealth to your webdriver
stealth(driver,
languages=["en-US", "en"],
vendor="Google Inc.",
platform="Win32",
webgl_vendor="Intel Inc.",
renderer="Intel Iris OpenGL Engine",
fix_hairline=True,
)
# Navigate to target
driver.get('https://www.snipesusa.com/')
# Give it some time to load
time.sleep(10)
# Take screenshot of page
driver.get_screenshot_as_file('stealth.png')
# Close browser
driver.quit()
Running the script returned some different outcomes for me this time, as opposed to the default Selenium settings:
The second option you may use is `undetected_chromedriver`. This one is described as an ‘optimized Selenium chromedriver. Let’s test it out:
# Install undetected_chromedriver
~ » python3 -m pip install undetected_chromedriver
The code is very similar to our default script. The main difference stands in the package name. Here is a basic scraper with `undetected_chromedriver` and let’s see if it can bypass Cloudflare:
import undetected_chromedriver as uc
import time
# Set Chrome to open in headless mode
options = uc.ChromeOptions()
options.headless = True
# Create a new Chrome instance and maximize the window
driver = uc.Chrome(options=options, executable_path='/Applications/Google Chrome.app/Contents/MacOS/Google Chrome')
driver.maximize_window()
# Navigate to target
driver.get('https://www.snipesusa.com/')
# Give it some time to load
time.sleep(10)
# Take screenshot of page
driver.get_screenshot_as_file('stealth-uc.png')
# Close browser
driver.quit()
Yet again, running the script turns out well for me. It seems that at least these two packages can successfully bypass Cloudflare protection. At least in the short term. Truth be told, chances are, if you use these scripts extensively, Cloudflare will catch up on your IP address and block it. So let me introduce you to a third option: Web Scraping API.
1.2. Selenium with Web Scraping API
Web Scraping API has this amazing feature called the Proxy Mode. You can read more about it here. But what I want to note here is that our Proxy Mode can successfully be integrated with Selenium. This way, you get access to all the evasion features we’ve implemented. And let me tell you that we have a dedicated team working on custom evasion techniques. In technical terms, we’re handling IP rotations, we’re using various proxies, we’re solving captchas and we’re using Chrome’s API to continuously change our fingerprint. In non-technical terms, this translates to less hassle on your side and a greater success rate. You basically get the stealthiest version of Selenium there is. And here’s how it’s done:
# Install selenium-wire
~ » python3 -m pip install selenium-wire
We’re using `selenium-wire` in order to use Selenium with a proxy. Now here’s the script:
from seleniumwire import webdriver
import time
# Method to encode parameters
def get_params(object):
params = ''
for key,value in object.items():
if list(object).index(key) < len(object) - 1:
params += f"{key}={value}."
else:
params += f"{key}={value}"
return params
# Your WSA API key
API_KEY = '<YOUR_API_KEY>'
# Default proxy mode parameters
PARAMETERS = {
"proxy_type":"datacenter",
"device":"desktop",
"render_js":1
}
# Set Selenium to use a proxy
options = {
'proxy': {
"http": f"http://webscrapingapi.{ get_params(PARAMETERS) }:{ API_KEY }@proxy.webscrapingapi.com:80",
}
}
# Create a new Chrome instance
driver = webdriver.Chrome(seleniumwire_options=options)
# Navigate to target
driver.get('https://www.httpbin.org/get')
# Retrieve the HTML documeent from the page
html = driver.page_source
print(html)
# Close browser
driver.quit()
If you run this script a couple of times, you’ll see how the IP address changes every time. That’s our IP rotation system. In the background, it also adds evasions techniques. You don’t even need to worry about them. We handle the Cloudflare bypassing part so that you can focus more on parsing the data.
Conclusions
If you want to build a scraper that can bypass Cloudflare, you need to account for a lot of things. A dedicated team can work 24/7 and there’s still no guarantee the evasions will work every time. That’s because, with every browser version release, there is a chance new features are added to the API. And some of these features can be used to fingerprint and detect bots.
I’d even say that the best browser to bypass Cloudflare and other providers is the one you build yourself. And we built one at Web Scraping API. Now we’re sharing it with you. So enjoy scraping!
News and updates
Stay up-to-date with the latest web scraping guides and news by subscribing to our newsletter.
We care about the protection of your data. Read our Privacy Policy.

Related articles

Effortlessly gather real-time data from search engines using the SERP Scraping API. Enhance market analysis, SEO, and topic research with ease. Get started today!


Explore the complexities of scraping Amazon product data with our in-depth guide. From best practices and tools like Amazon Scraper API to legal considerations, learn how to navigate challenges, bypass CAPTCHAs, and efficiently extract valuable insights.


Learn how to use proxies with Axios & Node.js for efficient web scraping. Tips, code samples & the benefits of using WebScrapingAPI included.