CSS Selectors Cheat Sheet - How to scrape the web tips and tricks
Ștefan Răcila on Dec 15 2022

Before writing a web scraper, you need to understand the data you are going to scrape and how to access that data. There are many ways in which you can access data in a web page, the most common one is to use CSS Selectors. Another alternative is to use XPath. You can find the XPath Cheat Sheet here.
Introduction to the DOM
In the process of parsing an HTML file, the browser creates a data representation in its memory that looks like a tree. This representation is called the DOM (Document Object Model). For every HTML tag, there is a node paired with it in the DOM. A node has properties like name, content, child nodes, styles, events etc. You can find more information about how browser rendering works on this article How browser rendering works — behind the scenes.
When we say that we want to access data from a web page, we only want to iterate through the DOM to a specific set of nodes and extract the content inside them. In this article I will tell you different tips on how to access those nodes quickly using CSS Selectors.
What are CSS Selectors?
Why are they named CSS (Cascading Style Sheets) Selectors in the first place?
CSS is used to define the appearance of nodes on a page. With CSS you can write rules about what a node's appearance should be and how it should interact with other nodes. A rule is composed of a selector and a list of styles to overwrite.
So, these selectors are associated with CSS because this is their most common use, but we don’t need to use them with just CSS. With CSS you want to select a node and change its style property. If you think about it, we want to do the same thing: select a node and do something with it, like read its contents or trigger an event.
How do CSS Selectors work?
It will help you greatly if you visualize the selection happening. Let’s say that you want to scrape all paragraphs from a website. You want to get all nodes that have the name `p`. You can do that by hand. You just need to iterate through every node on the DOM and select only the nodes that have node.tagName === 'P' (tag names are uppercase).
Here is a short code snippet that you can use:
function scrapeByTagName(node, tagName) {
if (node === null)
return;
node.childNodes.forEach(node => {
//console.log(node.tagName)
if (node.tagName?.toLowerCase() === tagName.toLowerCase()) {
console.log(node)
return
}
scrapeByTagName(node, tagName)
});
}I made a dummy web page that looks like this:

And here is the HTML for it:
<!DOCTYPE html>
<html lang="en">
<head>
<link rel="stylesheet" href="styles.css">
<script src="script.js"></script>
</head>
<body>
<div id="wrapper">
<h1 custom-attr="some data">Some Title</h1>
<h2 custom-attr="some other data">Some Subtitle</h2>
<div id="container">
<p custom-attr>paragraph
<span> subparagraph</span>
</p>
<p id="text">paragraph with id #text</p>
<p class="bold">paragraph with class .bold</p>
<p class="text">paragraph with class .text</p>
<p class="text bold">paragraph with class .text.bold</p>
<p class="text italic">paragraph with class .text.italic</p>
</div>
</div>
</body>
</html>
After I ran the function in the browser console, I got this response:
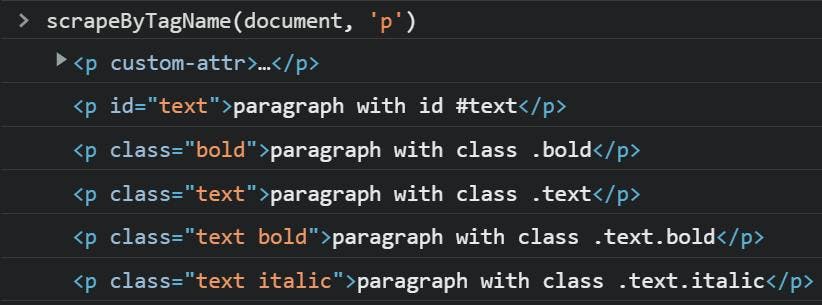
As you can see, the function logged all the p tags.
To see the browser console you need to open devTools and go to the console tab or press escape. You can open devTools by right clicking an element and choosing inspect from the menu or by using the keyboard shortcut control + shift + i.
How to use CSS Selectors?
We will use two methods: querySelector and querySelectorAll. These methods appear on every object with type Element. The nodes we are trying to scrape have type HTMLElement which inherits from type Element.
querySelector will return the first node that matches the selector. querySelectorAll will return a list with all the nodes that match the selector. To replicate the example previously shown we just need to call querySelectorAll and iterate through the returned list.
document.querySelectorAll('p').forEach(node => console.log(node))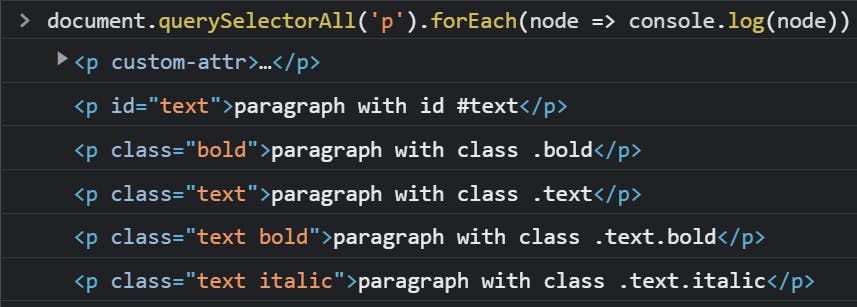
You can see that I used document.querySelectorAll, that’s because document is defined in the window context to be the root of the web page a.k.a. the correspondent of the html tag. You can use querySelector methods with every node, not only with the root node.
To actually scrape something you will need to use a library that can open a browser window and go to an url. Only then your code will execute, in the context of that window. To learn more about how to do this I recommend this article The Ultimate Guide to Web Scraping with JavaScript and Node.Js.
Here at WebScrapingAPI we use Puppeteer. Puppeteer is a library that lets us control instances of headless Chromium browsers. You can use our API to extract data from a website without building a custom scraper. We actually have a parameter named extract_rules that uses CSS Selectors to extract data from a given URL.
The CSS Selectors Cheat Sheet
The * selector
This selector specifies all elements from the tree. It does not have much usage but is good to know.
The .class selector
You can get a node with a specific class by using .class. It is mostly used when you have a list of items. Because the items in a list are likely to look the same, they might have the same class. Let’s search for the .text class.

Maybe you want to select the node that has the .bold class.

It looks like there is another element that has the .bold class. You can be more specific with the class selector by using multiple classes concatenated.

Please note that there are no spaces between classes.
document.querySelectorAll('.text .bold').forEach(node => console.log(node))This query does not return anything from the HTML above, because it looks for an element with class .text that has a child with .bold class (not necessarily a direct child). The query would return the child element if found.
The #id selector
What if an element doesn't have a class or if the class is used too frequently in the document? You can use the ID attribute to achieve a deeper level of specificity. The drawback of using the id selector is that, in most cases, the id is unique in the HTML page so you can’t get a list of nodes with it.

The Node Name Selector
Every node has a name. It is the exact name of the paired tag in the HTML. You can get all nodes that have a specific name by using their name in the selector.

The [attribute] selector
You might encounter situations in which you would want to select all the nodes that have some specific attribute.

You can also specify the attribute value.

Or even what the attribute value should contain. You can use tilde ~ before the equals sign to define that the attribute value should contain a list of words.

The attribute selector will be the most used if you decide to build a scrapper. It is very powerful and it has a lot more use cases than what I showed here. You can find more information about how to use the attribute selector here W3 Attribute Selectors.
Grouping Multiple Selectors
Getting all the p nodes that have an id.

Select all span nodes that are child of a p node.

Get all div nodes that are direct childs of the body node.

Get all p nodes that have class .text

The options of grouping these selectors are endless. Try to copy the HTML code from above and add more nodes to it. Then try different selectors combinations. If you want to learn more about CSS selectors in general, Mozilla offers a fantastic article that explains how CSS selectors work for web development.
Summary
If you want to learn something new I advise you to learn how that thing works first. Yes, it is an optional step, but it will give you some information that others don’t have.
In the field of software development this information will help you search for the right answer to your problem/error. You could take the matter into your own hands and even create a custom solution.
If you really want to understand CSS selectors you need to understand the DOM. It is just a tree (a connected acyclic undirected graph) with nodes that have a name and some attributes. That’s it. When you write a selector, you just write a string that is parsed and used to query the DOM.
News and updates
Stay up-to-date with the latest web scraping guides and news by subscribing to our newsletter.
We care about the protection of your data. Read our Privacy Policy.

Related articles

Learn how to scrape dynamic JavaScript-rendered websites using Scrapy and Splash. From installation to writing a spider, handling pagination, and managing Splash responses, this comprehensive guide offers step-by-step instructions for beginners and experts alike.


Are XPath selectors better than CSS selectors for web scraping? Learn about each method's strengths and limitations and make the right choice for your project!


Learn how to scrape HTML tables with Golang for powerful data extraction. Explore the structure of HTML tables and build a web scraper using Golang's simplicity, concurrency, and robust standard library.
