TL;DR: Cloudflare blocks scrapers by layering TLS fingerprinting, JavaScript challenges, behavioral analysis, and Turnstile CAPTCHAs into a composite trust score. To bypass Cloudflare reliably, you need to match every layer simultaneously. This guide covers the detection stack, compares four practical tools (Nodriver, SeleniumBase UC, Camoufox, curl-impersonate), and walks through proxy strategies, session persistence, error troubleshooting, and production scaling.
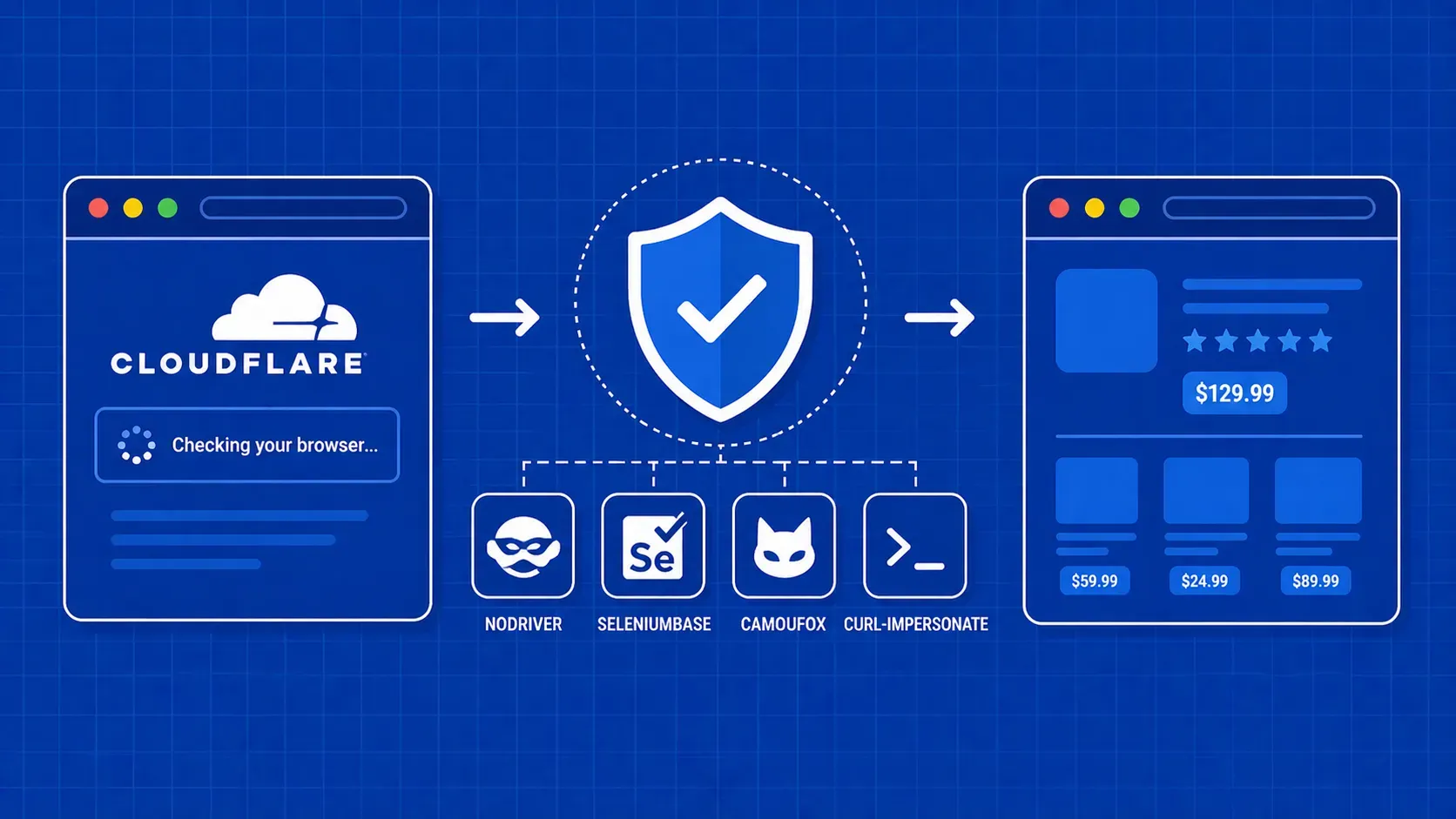
Cloudflare Bot Management is a multi-layered detection system that identifies and blocks automated traffic by combining TLS fingerprinting, JavaScript execution checks, behavior analysis, IP reputation scoring, and Turnstile CAPTCHAs into a single trust score. If you have tried to scrape a Cloudflare-protected site with a basic HTTP library or vanilla Selenium, you know how quickly that request gets shut down.
The challenge in 2026 is that no single trick beats Cloudflare anymore. Each request passes through overlapping checks, and your scraper needs to look legitimate at every layer simultaneously. A mismatched TLS fingerprint, a missing JavaScript API, or an unnatural navigation pattern is enough to trigger a block.
This guide breaks down how Cloudflare identifies bots, then walks through four practical tools to bypass Cloudflare bot protection with working Python code. You will also find proxy rotation strategies, session persistence techniques, a full error-code troubleshooting table, and guidance on when a managed service makes more sense than DIY.