The Ultimate Playwright Web Scraping and Automation Guide for 2023
Suciu Dan on Apr 21 2023

Web scraping and automation go hand in hand in today's digital world. From price comparison websites to data-driven businesses, the ability to extract and process data from the web has become an integral part of many online ventures.
Enter Playwright: a tool that allows you to automate web scraping and testing tasks with ease. Playwright allows you to control a headless browser, giving you the ability to scrape data and interact with websites in a fast and efficient manner.
In this article, we will explore the capabilities of Playwright for automation and scraping. I will show you how to install and set up Playwright, provide code samples for common tasks, and discuss advanced techniques such as handling login forms, taking screenshots, and more.
What is Playwright?
Playwright is an open-source cross-platform Node.js library developed by Microsoft that allows you to automate tasks in a web browser. It is designed to be reliable and easy to use, with support for modern web features such as CSS3 and JavaScript.
Playwright can be used for tasks such as testing web applications, automating web-based tasks, and web scraping. It is built on top of the popular web testing library Puppeteer and aims to provide a more user-friendly and maintainable API.
Playwright supports multiple browsers, including Chromium, Firefox, and WebKit. This means you can use it to automate tasks and scrape data on different browsers. Playwright allows you to easily switch between browsers and take advantage of their unique features.
Getting Started
To install and set up Playwright on a local machine, you will need to have Node.js and npm (the package manager for Node.js) installed. If you don't have these already, you can download and install them from the official Node.js website.
Once you have Node.js and npm installed, you can install Playwright using the following steps:
- Open a terminal or command prompt
- Create a folder called `playwright` where our project code will live
- Go to the newly created folder
- Run the command `npm init` to initialise the project (and create the package.json file)
- Install the required dependency using the command `npm install playwright`
Basic Scraping with Playwright
Create a file called `index.js` and paste the following code:
const { chromium } = require('playwright');
(async () => {
// Launch a Chromium browser
const browser = await chromium.launch();
// Create a new page in the browser
const page = await browser.newPage();
// Navigate to a website
await page.goto('https://coinmarketcap.com');
// Get the page content
const content = await page.content();
// Display the content
console.log(content);
// Close the browser
await browser.close();
})();This code will launch a headless Chromium browser, create a new page, navigate to the CoinMarketCap homepage, get the page content, log the content, and then close the browser.
You can use similar code to launch the other supported browsers (Firefox and WebKit) by requiring the appropriate module and replacing "chromium" with "firefox" or "webkit".
Finding Elements for Data Extraction
Now that we have a foundation for our scraper, let's extract some data from the target website. In this example, we will retrieve the name and price of the first 10 currencies displayed on the page.
To view the DOM tree of the CoinMarketCap homepage, open the website in a browser, right-click on a currency name, and select "Inspect". This will open the Developer Tools and display the DOM tree.
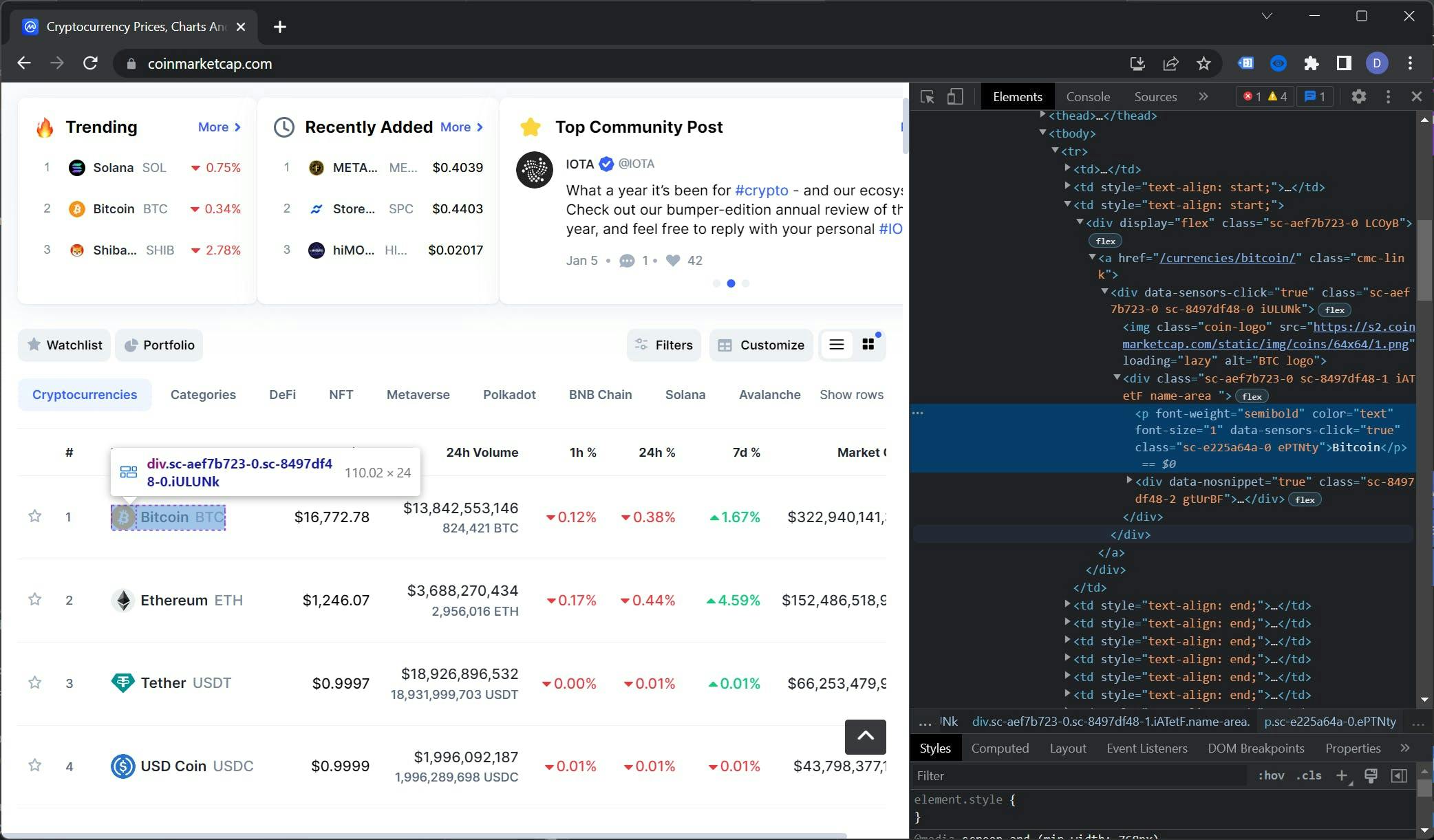
Selecting the right selectors is an art in itself. In this case, the table element that we want to select is the context. This table has a class called "cmc-table" which will be useful for our purposes.
To find the selector for the currency name, we will need to move down the DOM tree. The element we’re looking for is located within the `.cmc-table tbody tr td:nth-child(3) a .name-area p` element.
As a general rule of thumb, it's important to be as accurate as possible when selecting elements, as this will minimise the number of errors that need to be handled.
Using the same technique, we can find the selector for the price which is `.cmc-table tbody tr td:nth-child(3) a span`. To recap, here’s our selector list:
- Name: `.cmc-table tbody tr td:nth-child(3) a .name-area p`
- Price: `.cmc-table tbody tr td:nth-child(4) a span`
Data Extraction
Using the selectors we identified earlier, let's extract the data from the webpage and store it in a list. The $$eval utility function returns an array of elements matching a selector, evaluated in the context of the page's DOM.
Let’s replace the console.log(content); line with this:
// Extract the currencies data
const currencies = await page.$$eval('.cmc-table tbody tr:nth-child(-n+10)', trs => {
const data = []
trs.forEach(tr => {
data.push({
name: tr.querySelector('td:nth-child(3) a .name-area p').innerHTML,
price: tr.querySelector('td:nth-child(4) a span').innerHTML,
})
})
return data
})
// Display the results
console.log(currencies)
This code uses the $$eval function to select the first 10 tr elements within the .cmc-table. It then iterates over these elements, selects the table data cells using the selectors we identified earlier, and extracts their text content. The data is returned as an array of objects.
You can read more about the $$eval function in the official documentation.
The full code looks like this:
const { chromium } = require('playwright');
(async () => {
// Launch a Chromium browser
const browser = await chromium.launch();
// Create a new page in the browser
const page = await browser.newPage();
// Navigate to a website
await page.goto('https://coinmarketcap.com');
// Extract the currencies data
const currencies = await page.$$eval('.cmc-table tbody tr:nth-child(-n+10)', trs => {
const data = []
trs.forEach(tr => {
data.push({
name: tr.querySelector('td:nth-child(3) a .name-area p').innerHTML,
price: tr.querySelector('td:nth-child(4) a span').innerHTML,
})
})
return data
})
// Display the results
console.log(currencies)
// Close the browser
await browser.close();
})();Handling Dynamic Content
We only scraped the first 10 currencies because that is how many CoinMarketCap loads on the initial page load. To scrape more, we need to do a human action which is scrolling the page. Fortunately, Playwright is well-suited for this task.
Let’s start by refactoring the $$eval function we previously used and implementing pagination. We’ll call this new function extractData:
const extractData = async (page, currentPage, perPage = 10) => {
}We extend the :nth-child selector by selecting items in steps (elements from 0 to 10, from 11 to 21, from 22 to 32, etc). We define the initial selector (first 10 elements):
let selector = `:nth-child(-n+${currentPage * perPage})`;Last but not least, we add support for the next pages. The code looks like this:
if(currentPage > 1) {
selector = `:nth-child(n+${(currentPage - 1) + perPage}):nth-child(-n+${(currentPage * perPage) + 1})`;
}The final function will look like this:
const extractData = async (page, currentPage, perPage = 10) => {
let selector = `:nth-child(-n+${currentPage * perPage})`;
if(currentPage > 1) {
selector = `:nth-child(n+${(currentPage - 1) + perPage}):nth-child(-n+${(currentPage * perPage) + 1})`;
}
return await page.$$eval(`.cmc-table tbody tr${selector}`, trs => {
const data = [];
trs.forEach(tr => {
data.push({
name: tr.querySelector('td:nth-child(3) a .name-area p').innerHTML,
price: tr.querySelector('td:nth-child(4) a span').innerHTML,
});
});
return data;
});
};Now it’s time to go back to our scraper code, implement scroll, and extend the data extraction. We do all the work after this line:
await page.goto('https://coinmarketcap.com');We redefine the currencies variable:
// Extract the currencies data
let currencies = await extractData(page, 1, 10);
Using the evaluate function, we scroll the page to 1.5x of the viewport. This will trigger the next elements from the table to load:
// Scroll the page to a little more than the viewport height
await page.evaluate(() => {
window.scrollTo(0, window.innerHeight * 1.5);
});
The one second of waiting will give the UI some room to populate the table with the data retrieved from the API:
// Wait for the new elements to load
await page.waitForTimeout(1000);
Finally, let’s extract the data from the second page and log the results:
// Extract the next 10 elements
currencies = [...currencies, ...await extractData(page, 2, 10)]
// Display the results
console.log(currencies)
The full code for the scraper should look like this:
const { chromium } = require('playwright');
const extractData = async (page, currentPage, perPage = 10) => {
let selector = `:nth-child(-n+${currentPage * perPage})`;
if(currentPage > 1) {
selector = `:nth-child(n+${(currentPage - 1) + perPage}):nth-child(-n+${(currentPage * perPage) + 1})`;
}
return await page.$$eval(`.cmc-table tbody tr${selector}`, trs => {
const data = [];
trs.forEach(tr => {
data.push({
name: tr.querySelector('td:nth-child(3) a .name-area p').innerHTML,
price: tr.querySelector('td:nth-child(4) a span').innerHTML,
});
})
return data;
})
};
(async () => {
// Launch a Chromium browser
const browser = await chromium.launch();
// Create a new page in the browser
const page = await browser.newPage();
// Navigate to a website
await page.goto('https://coinmarketcap.com');
// Extract the currencies data
let currencies = await extractData(page, 1, 10)
// Scroll the page to a little more than the viewport height
await page.evaluate(() => {
window.scrollTo(0, window.innerHeight * 1.5);
});
// Wait for the new elements to load
await page.waitForTimeout(1000);
// Extract the next 10 elements
currencies = [...currencies, ...await extractData(page, 2, 10)];
// Display the results
console.log(currencies);
// Close the browser
await browser.close();
})();To recap, the scraper will open the CoinMarketCap home page, extract the data from the first 10 currencies, scroll the page, extract the data from the next 10 currencies and display the results.
You should get similar results to these:
[
{ name: 'Bitcoin', price: '$16,742.58' },
{ name: 'Ethereum', price: '$1,244.45' },
{ name: 'Tether', price: '$0.9997' },
{ name: 'USD Coin', price: '$1.00' },
{ name: 'BNB', price: '$255.78' },
{ name: 'XRP', price: '$0.335' },
{ name: 'Binance USD', price: '$1.00' },
{ name: 'Dogecoin', price: '$0.07066' },
{ name: 'Cardano', price: '$0.2692' },
{ name: 'Polygon', price: '$0.7762' },
{ name: 'Dai', price: '$0.9994' },
{ name: 'Litecoin', price: '$73.80' },
{ name: 'Polkadot', price: '$4.59' },
{ name: 'Solana', price: '$12.95' },
{ name: 'TRON', price: '$0.0505' },
{ name: 'Shiba Inu', price: '$0.000008234' },
{ name: 'Uniswap', price: '$5.29' },
{ name: 'Avalanche', price: '$11.43' },
{ name: 'UNUS SED LEO', price: '$3.47' },
{ name: 'Wrapped Bitcoin', price: '$16,725.03' },
{ name: 'Cosmos', price: '$9.97' }
]
Advanced Techniques
Now that we've covered the basics of web scraping with Playwright, such as creating a scraper, finding selectors, extracting data, and implementing infinite scrolling, it's time to delve into some of the more advanced features that Playwright has to offer.
These include taking screenshots, filling forms, using XPaths instead of class selectors, and using proxies to bypass IP blocks.
Taking a Screenshot
One of the advantages of taking screenshots while web scraping is that it allows you to see how a site or web application looks in different browsers and resolutions.
This can be particularly useful for developers, who can use screenshots to debug layout issues and test the appearance of their web applications on different platforms.
To take a full-page screenshot, you can use the screenshot method of the Page object. Here is an example:
const screenshot = await page.screenshot();
This code takes a screenshot of the entire page and returns it as a Buffer. The `screenshot` function accepts properties. We can define the path where we want the screenshot saved and if the screenshot should contain just the viewport or the entire page.
This is the full code:
const { chromium } = require('playwright');
(async () => {
const browser = await chromium.launch();
const page = await browser.newPage();
await page.goto('https://coinmarketcap.com');
// Take a full page screenshot and save the file
await page.screenshot({
path: "screenshot.png",
fullPage: false
});
await browser.close();
})();You can store this code in a file called `screenshot.js` and run the code with the command `node screenshot.js`. After execution, a `screenshot.png` file will be created in your project folder.
We can take a screenshot of an area from the page by using the `clip` property. We need to define four properties:
- x: the horizontal offset from the top left corner
- y: the vertical offset from the top left corner
- width: the area width
- height: the area height
The screenshot function with the clip property set will look like this:
// Take a screenshot of a part of the page
await page.screenshot({
path: "screenshot.png",
fullPage: false,
clip: {
x: 50,
y: 50,
width: 320,
height: 160
}
});
Filling Forms
One of the benefits of using Playwright is that it allows you to access protected pages. By emulating human actions such as clicking buttons, scrolling the page, and filling out forms, Playwright can bypass login requirements and access restricted content.
Let’s use Playwright to access our Reddit account (if you don’t have a Reddit account, make one right now!).
Go to the login page and use the techniques we learned in the "Finding Elements for Data Extraction" section to extract the classes for the username and password inputs.
The selectors should look like this:
- Username input: `#loginUsername`
- Password input: `#loginPassword`
- Submit button: `button[type=”submit”]`
Let’s use these selectors in the code. Create a `login.js` file and paste this code:
const { chromium } = require('playwright');
(async () => {
const browser = await chromium.launch();
const page = await browser.newPage();
await page.goto('https://reddit.com/login');
// Fill up the form
await page.fill('#loginUsername', "YOUR_REDDIT_USERNAME");
await page.fill('#loginPassword', "YOUR_REDDIT_PASSWORD");
// Click the submit button
await page.click('button[type="submit"]');
// Wait for the new page to load
await page.waitForNavigation()
// Take a screenshot of the new page
await page.screenshot({
path: "reddit.png",
fullPage: false
});
// Close the browser
await browser.close();
})();To run the code and take a screenshot of the protected page, simply enter node login.js in the terminal. After a few seconds, a screenshot named reddit.png will appear in your project directory.
Unfortunately, I can't share the resulting screenshot with you, as most of my Reddit account is not safe for work.
You can read more about authentication with Playwright in the official documentation.
Using XPath for Data Extraction
XPath can be a more stable choice for web scraping because it is less likely to change than class names. Websites like Reddit and Google often update their class names, which can cause issues for scrapers that depend on them.
In contrast, XPath expressions are based on the structure of the HTML document and are less likely to change. This means that you can use XPath to identify elements in a more reliable and stable manner, even on websites that frequently update their class names.
As a result, using XPath can help you build a more robust and resilient web scraper that is less prone to breaking when the website updates.
We will only scratch the surface of what you can do with XPath in this article. For a more comprehensive guide, check out this article.
Let’s go back to Reddit, open a subreddit and open the Developer Tools. I will use the /r/webscraping subreddit, but you can pick any subreddit you want.
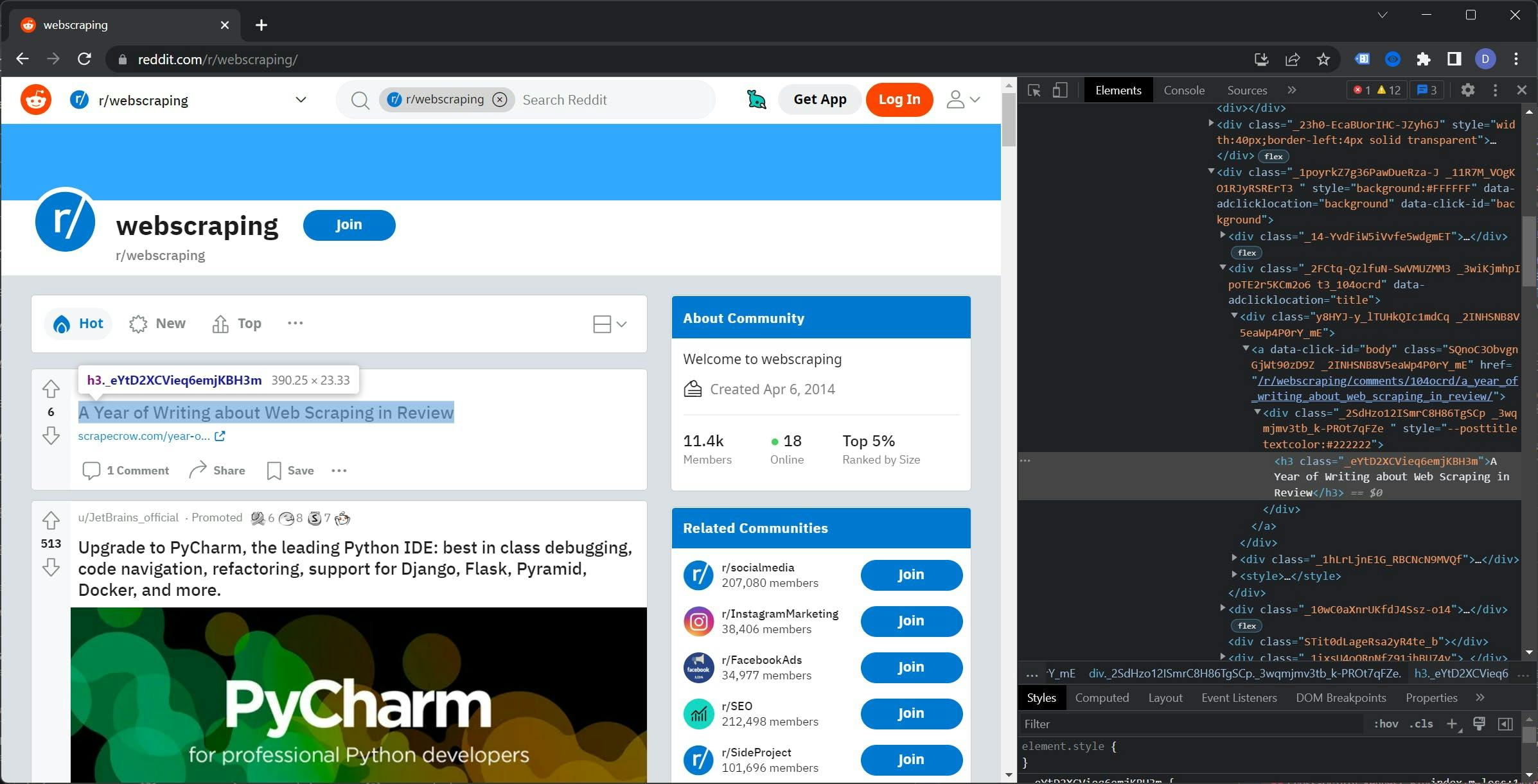
If you examine the DOM tree, you may notice that the classes for the elements appear to be randomly generated. Using these classes would decrease the reliability of the scraper and require ongoing maintenance.
Right-click on the `h3` tag, go to Copy, and select `Copy XPath`. The result should look like this:
//*[@id="t3_104ocrd"]/div[3]/div[2]/div[1]/a/div/h3
Before we use this rule, let’s remove the @id part so the path covers all the posts and not just the first one.
Time to put it to work. Create the `xpath.js` file and paste this code:
const { chromium } = require('playwright');
(async () => {
const browser = await chromium.launch();
const page = await browser.newPage();
await page.goto('https://reddit.com/r/webscraping');
const titles = await page.$$eval("//*/div[3]/div[2]/div[1]/a/div/h3", element => {
const data = []
element.forEach(el => {
data.push(el.innerHTML)
})
return data
})
console.log(titles)
// Close the browser
await browser.close();
})();To run the code, use the `node xpath.js` command. This will return a list of titles from the subreddit you selected. For example, my list looks like this:
[
'A Year of Writing about Web Scraping in Review',
'Linkedin Comments Scraper - Script to scrape comments (including name, profile picture, designation, email(if present), and comment) from a LinkedIn post from the URL of the post.',
'Best Proxy Lists?',
'Sorry if this is the wrong sub, but is it possible to extract an email from an old youtube account?',
'Looking for people with datasets for sale!',
"Are reddit's classes names change periodically (those with random letters and numbers and what not)",
'Scrape Videos from multiple websites',
'Anyone want to write me a program that can automate generating a pdf of a magazine subscription?',
'Scraping a Dynamic Webpage with rSelenium',
'Is there a way to convert LinkedIn Sales Navigator URLs to a LinkedIn public URL?',
'Gurufocus / Implemented new cloudflare protection?',
'Scraper to collect APY data from Web3 frontends'
]
You can read more about XPath in the official Playwright documentation. You can find it here.
Playwright vs The Others
Playwright, Puppeteer, and Selenium WebDriver are all tools that can be used for web scraping and automation.
Playwright, developed by Microsoft, is a newer tool that aims to be a "complete" solution for web automation. It supports multiple browsers (Chromium, Firefox, and WebKit) and multiple programming languages (JavaScript, TypeScript, Python, and C#).
Puppeteer is a tool developed by Google for web scraping and automation that is built on the Chrome DevTools Protocol. It is used primarily with JavaScript and has many features including taking screenshots, generating PDFs, and interacting with the DOM.
Selenium WebDriver is a tool for web automation and testing that supports multiple programming languages and browsers. It is geared towards testing and may require more setup than some other tools.
Comparing the Performance
Performance is an important consideration when choosing a web scraping tool. In this section, we will compare the performance of Playwright, Puppeteer, and Selenium WebDriver to see which tool is the fastest and most efficient.
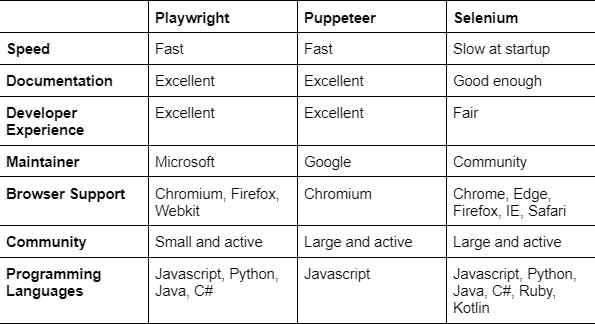
During our testing, we found that Playwright and Puppeteer had almost identical response times when it came to web scraping and automation tasks. However, Selenium WebDriver was significantly slower at startup compared to the other two tools.
Conclusion
Web scraping allows you to extract and process data from websites, providing a wealth of information and opportunities for businesses and individuals. Some benefits of web scraping include:
- Cost savings: Web scraping can be a cost-effective way to gather data, as it allows you to bypass the need to purchase expensive databases or APIs.
- Time efficiency: Scraping large amounts of data can be done much faster than manually collecting it.
- Up-to-date data: Web scraping can help you keep your data up to date by allowing you to regularly scrape and refresh your data sources.
Playwright is a powerful tool for web scraping, offering a variety of features that make it a top choice for many users. Some advantages of using Playwright include:
- Compatibility with Chromium: Playwright is built on top of Chromium, the open-source browser project that powers Google Chrome, giving you access to the latest web platform features and a wide range of compatibility with websites.
- Cross-browser support: Playwright allows you to automate tasks across multiple browsers, including Chrome, Firefox, and Safari.
- Ease of use: Playwright has a simple and intuitive API, making it easy to get started with web scraping and automation tasks.
- Versatility: Playwright can be used for a wide range of tasks, including web scraping, testing, and automation.
Overall, the benefits of web scraping and the advantages of using Playwright make it an essential tool for anyone looking to extract and process data from the web.
If you're looking for an easier solution for your web scraping needs, consider using WebScrapingAPI. Our service allows you to scrape data from any website without the need to deal with the complexities of setting up and maintaining a web scraper.
With WebScrapingAPI, you can simply send an HTTP request to our API with the URL of the website you want to scrape, and we'll return the data to you in your preferred format (JSON, HTML, PNG).
Our API handles all the heavy lifting for you, including bypassing CAPTCHAs, handling IP blocks, and handling dynamic content.
So why waste time and resources building and maintaining your own web scraper when you can use WebScrapingAPI and get the data you need with just a few simple API requests? Give us a try and see how we can help streamline your web scraping needs.
News and updates
Stay up-to-date with the latest web scraping guides and news by subscribing to our newsletter.
We care about the protection of your data. Read our Privacy Policy.

Related articles

Explore the complexities of scraping Amazon product data with our in-depth guide. From best practices and tools like Amazon Scraper API to legal considerations, learn how to navigate challenges, bypass CAPTCHAs, and efficiently extract valuable insights.


Explore the in-depth comparison between Scrapy and Selenium for web scraping. From large-scale data acquisition to handling dynamic content, discover the pros, cons, and unique features of each. Learn how to choose the best framework based on your project's needs and scale.


Learn what’s the best browser to bypass Cloudflare detection systems while web scraping with Selenium.
