How to Web Scrape Idealista: A Comprehensive Guide (2023 Update)
Raluca Penciuc on Mar 03 2023

Idealista is one of the leading real estate websites in Southern Europe, providing a wealth of information on properties for sale and rent. It’s available in Spain, Portugal, and Italy, listing millions of homes, rooms, and apartments.
For businesses and individuals looking to gain insights into the Spanish property market, the website can be a precious tool. Web scraping Idealista can help you extract this valuable information and use it in various ways such as market research, lead generation, and creating new business opportunities.
In this article, we will provide a step-by-step guide on how to scrape the website using TypeScript. We will cover the prerequisites, the actual scraping of properties data and how to improve the process, and why using a professional scraper is better than creating your own.
By the end of the article, you will have the knowledge and tools to extract data from Idealista and make good use of it for your business.
Prerequisites
Before we begin, let's ensure we have the necessary tools.
First, download and install Node.js from the official website, making sure to use the Long-Term Support (LTS) version. This will also automatically install Node Package Manager (NPM) which we will use to install further dependencies.
For this tutorial, we will be using Visual Studio Code as our Integrated Development Environment (IDE) but you can use any other IDE of your choice. Create a new folder for your project, open the terminal, and run the following command to set up a new Node.js project:
npm init -y
This will create a package.json file in your project directory, which will store information about your project and its dependencies.
Next, we need to install TypeScript and the type definitions for Node.js. TypeScript offers optional static typing which helps prevent errors in the code. To do this, run in the terminal:
npm install typescript @types/node --save-dev
You can verify the installation by running:
npx tsc --version
TypeScript uses a configuration file called tsconfig.json to store compiler options and other settings. To create this file in your project, run the following command:
npx tsc -init
Make sure that the value for “outDir” is set to “dist”. This way we will separate the TypeScript files from the compiled ones. You can find more information about this file and its properties in the official TypeScript documentation.
Now, create an “src” directory in your project, and a new “index.ts” file. Here is where we will keep the scraping code. To execute TypeScript code you have to compile it first, so to make sure that we don’t forget this extra step, we can use a custom-defined command.
Head over to the “package.json” file, and edit the “scripts” section like this:
"scripts": {
"test": "npx tsc && node dist/index.js"
}This way, when you will execute the script, you just have to type “npm run test” in your terminal.
Finally, to scrape the data from the website, we will use Puppeteer, a headless browser library for Node.js that allows you to control a web browser and interact with websites programmatically. To install it, run this command in the terminal:
npm install puppeteer
It is highly recommended when you want to ensure the completeness of your data, as many websites today contain dynamic-generated content. If you’re curious, you can check out before continuing the Puppeteer documentation to fully see what it’s capable of.
Locating the data
Now that you have your environment set up, we can start looking at extracting the data. For this article, I chose to scrape the list of houses and apartments available in a region from Toledo, Spain: https://www.idealista.com/pt/alquiler-viviendas/toledo/buenavista-valparaiso-la-legua/.
We’re going to extract the following data from each listing on the page:
- the URL;
- the title;
- the price;
- the details (number of rooms, surface, etc.);
- the description
You can see all this information highlighted in the screenshot below:
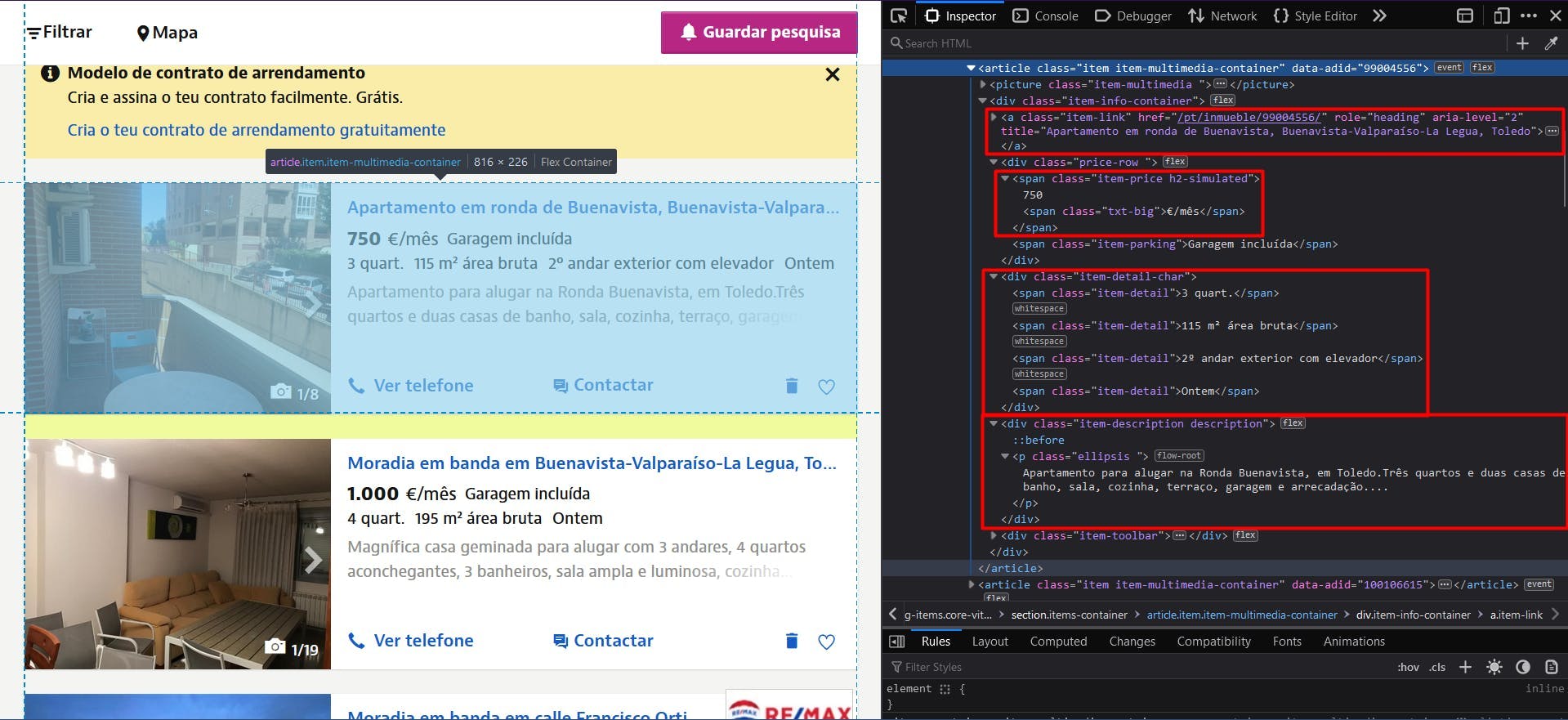
By opening the Developer Tools on each of these elements you will be able to notice the CSS selectors that we will use to locate the HTML elements. If you’re fairly new to how CSS selectors work, feel free to reach out to this beginner guide.
Data extraction
To start writing our script, let’s verify that the Puppeteer installation went all right:
import puppeteer from 'puppeteer';
async function scrapeIdealistaData(idealista_url: string): Promise<void> {
// Launch Puppeteer
const browser = await puppeteer.launch({
headless: false,
args: ['--start-maximized'],
defaultViewport: null
})
// Create a new page
const page = await browser.newPage()
// Navigate to the target URL
await page.goto(idealista_url)
// Close the browser
await browser.close()
}
scrapeIdealistaData("https://www.idealista.com/pt/alquiler-viviendas/toledo/buenavista-valparaiso-la-legua/")
Here we open a browser window, create a new page, navigate to our target URL, and close the browser. For the sake of simplicity and visual debugging, I open the browser window maximized in non-headless mode.
Since all listings have the same structure and data, we can extract all of the information for the entire properties list in our algorithm. After running the script, we can loop through all of the results and compile them into a single list.
To get the URL of all the properties, we locate the anchor elements with the “item-link” class. Then we convert the result to a JavaScript array and map each element to the value of the “href” attribute.
// Extract listings location
const listings_location = await page.evaluate(() => {
const locations = document.querySelectorAll('a.item-link')
const locations_array = Array.from(locations)
return locations ? locations_array.map(a => a.getAttribute('href')) : []
})
console.log(listings_location.length, listings_location)
Then, for the titles, we can make use of the same anchor element, except that this time we will extract its “title” attribute.
// Extract listings titles
const listings_title = await page.evaluate(() => {
const titles = document.querySelectorAll('a.item-link')
const titles_array = Array.from(titles)
return titles ? titles_array.map(t => t.getAttribute('title')) : []
})
console.log(listings_title.length, listings_title)
For the prices, we locate the “span” elements having 2 class names: “item-price” and “h2-simulated”. It’s important to identify the elements as unique as possible, so you don’t alter your final result. It needs to be converted to an array as well and then mapped to its text content.
// Extract listings prices
const listings_price = await page.evaluate(() => {
const prices = document.querySelectorAll('span.item-price.h2-simulated')
const prices_array = Array.from(prices)
return prices ? prices_array.map(p => p.textContent) : []
})
console.log(listings_price.length, listings_price)
We apply the same principle for the property details, parsing the “div” elements with the “item-detail-char” class name.
// Extract listings details
const listings_detail = await page.evaluate(() => {
const details = document.querySelectorAll('div.item-detail-char')
const details_array = Array.from(details)
return details ? details_array.map(d => d.textContent) : []
})
console.log(listings_detail.length, listings_detail)
And finally, the description of the properties. Here we apply an extra regular expression to remove all the unnecessary newline characters.
// Extract listings descriptions
const listings_description = await page.evaluate(() => {
const descriptions = document.querySelectorAll('div.item-description.description')
const descriptions_array = Array.from(descriptions)
return descriptions ? descriptions_array.map(d => d.textContent.replace(/(\r\n|\n|\r)/gm, "")) : []
})
console.log(listings_description.length, listings_description)
Now you should have 5 lists, one for each piece of data we scraped. As I mentioned before, we should centralize them into a single one. This way, the information we gathered will be much easier to further process.
// Group the lists
const listings = []
for (let i = 0; i < listings_location.length; i++) {
listings.push({
url: listings_location[i],
title: listings_title[i],
price: listings_price[i],
details: listings_detail[i],
description: listings_description[i]
})
}
console.log(listings.length, listings)
The final result should look like this:
[
{
url: '/pt/inmueble/99004556/',
title: 'Apartamento em ronda de Buenavista, Buenavista-Valparaíso-La Legua, Toledo',
price: '750€/mês',
details: '\n3 quart.\n115 m² área bruta\n2º andar exterior com elevador\nOntem \n',
description: 'Apartamento para alugar na Ronda Buenavista, em Toledo.Três quartos e duas casas de banho, sala, cozinha, terraço, garagem e arrecadação....'
},
{
url: '/pt/inmueble/100106615/',
title: 'Moradia em banda em Buenavista-Valparaíso-La Legua, Toledo',
price: '1.000€/mês',
details: '\n4 quart.\n195 m² área bruta\nOntem \n',
description: 'Magnífica casa geminada para alugar com 3 andares, 4 quartos aconchegantes, 3 banheiros, sala ampla e luminosa, cozinha totalmente equipa...'
},
{
url: '/pt/inmueble/100099977/',
title: 'Moradia em banda em calle Francisco Ortiz, Buenavista-Valparaíso-La Legua, Toledo',
price: '800€/mês',
details: '\n3 quart.\n118 m² área bruta\n10 jan \n',
description: 'O REMAX GRUPO FV aluga uma casa mobiliada na Calle Francisco Ortiz, em Toledo.Moradia geminada com 148 metros construídos, distribuídos...'
},
{
url: '/pt/inmueble/100094142/',
title: 'Apartamento em Buenavista-Valparaíso-La Legua, Toledo',
price: '850€/mês',
details: '\n4 quart.\n110 m² área bruta\n1º andar exterior com elevador\n10 jan \n',
description: 'Apartamento muito espaçoso para alugar sem móveis, cozinha totalmente equipada.Composto por 4 quartos, 1 casa de banho, terraço.Calefaç...'
}
]
Bypass bot detection
If you run your script at least 2 times during the course of this tutorial, you may have already noticed this annoying page:
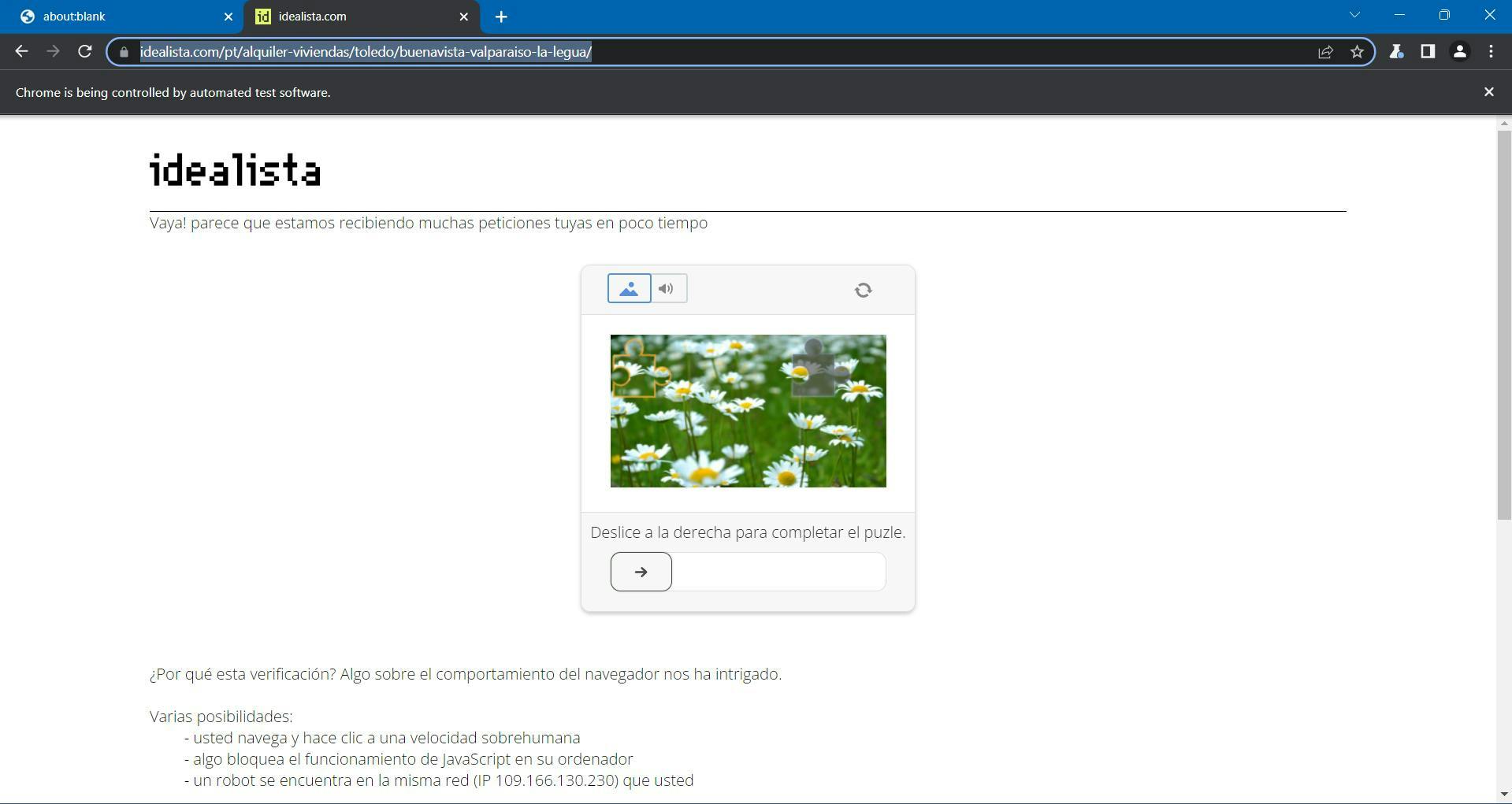
Idealista uses DataDome as its antibot protection, which incorporates a GeeTest CAPTCHA challenge. You’re supposed to move the piece of the puzzle until the image is complete, and then you should be redirected back to your target page.
You can easily pause your Puppeteer script until you solve the challenge using this code:
await page.waitForFunction(() => {
const pageContent = document.getElementById('main-content')
return pageContent !== null
}, {timeout: 10000})This tells our script to wait 10 seconds for a specified CSS selector to appear in the DOM. It should be enough for you to solve the CAPTCHA and then let the navigation to complete.
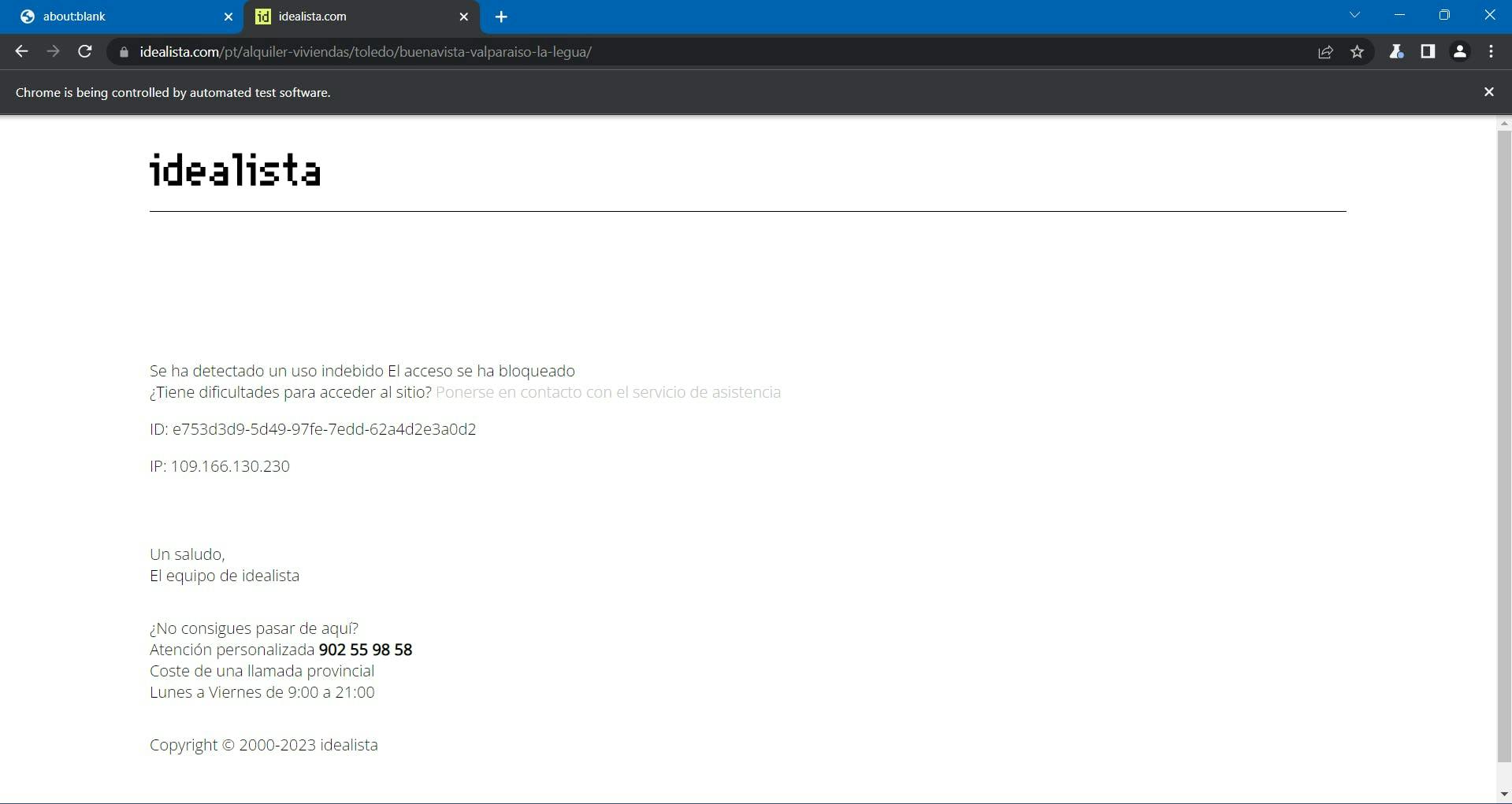
…Unless the Idealista page will block you anyway.
At this point, the process became more complex and challenging, and you didn’t even scale up your project.
As I mentioned before, Idealista is protected by DataDome. They collect multiple browser data to generate and associate you with a unique fingerprint. If they are suspicious, you receive the CAPTCHA challenge above, which is pretty difficult to automatically solve.
Among the collected browser data we find:
- properties from the Navigator object (deviceMemory, hardwareConcurrency, languages, platform, userAgent, webdriver, etc.)
- timing and performance checks
- WebGL
- WebRTC IP sniffing
- recording mouse movements
- inconsistencies between the User-Agent and your operating system
- and many more.
One way to overcome these challenges and continue scraping at a large scale is to use a scraping API. These kinds of services provide a simple and reliable way to access data from websites like Idealista.com, without the need to build and maintain your own scraper.
WebScrapingAPI is an example of such a product. Its proxy rotation mechanism avoids CAPTCHAs altogether, and its extended knowledge base makes it possible to randomize the browser data so it will look like a real user.
The setup is quick and easy. All you need to do is register an account, so you’ll receive your API key. It can be accessed from your dashboard, and it’s used to authenticate the requests you send.
As you have already set up your Node.js environment, we can make use of the corresponding SDK. Run the following command to add it to your project dependencies:
npm install webscrapingapi
Now all it’s left to do is to adjust the previous CSS selectors to the API. The powerful feature of extraction rules makes it possible to parse data without significant modifications.
import webScrapingApiClient from 'webscrapingapi';
const client = new webScrapingApiClient("YOUR_API_KEY");
async function exampleUsage() {
const api_params = {
'render_js': 1,
'proxy_type': 'residential',
'timeout': 60000,
'extract_rules': JSON.stringify({
locations: {
selector: 'a.item-link',
output: '@href',
all: '1'
},
titles: {
selector: 'a.item-link',
output: '@title',
all: '1'
},
prices: {
selector: 'span.item-price.h2-simulated',
output: 'text',
all: '1'
},
details: {
selector: 'div.item-detail-char',
output: 'text',
all: '1'
},
descriptions: {
selector: 'div.item-description.description',
output: 'text',
all: '1'
}
})
}
const URL = "https://www.idealista.com/pt/alquiler-viviendas/toledo/buenavista-valparaiso-la-legua/"
const response = await client.get(URL, api_params)
if (response.success) {
// Group the lists
const listings = []
for (let i = 0; i < response.response.data.locations.length; i++) {
listings.push({
url: response.response.data.locations[i],
title: response.response.data.titles[i],
price: response.response.data.prices[i],
details: response.response.data.details[i],
description: response.response.data.descriptions[i].replace(/(\r\n|\n|\r)/gm, "")
})
}
console.log(listings.length, listings)
} else {
console.log(response.error.response.data)
}
}
exampleUsage();
Conclusion
In this article, we have shown you how to scrape Idealista, a popular Spanish real estate website, using TypeScript and Puppeteer. We've gone through the process of setting up the prerequisites and scraping the data, and we discussed some ways to improve the code.
Web scraping Idealista can provide valuable information for businesses and individuals. By using the techniques outlined in this article, you can extract data such as property URLs, prices, and descriptions from the website.
Additionally, If you want to avoid the antibot measures and the complexity of the scraping process, using a professional scraper can be more efficient and reliable than creating your own.
By following the steps and techniques outlined in this guide, you can unlock the power of web scraping Idealista and use it to support your business needs. Whether it's for market research, lead generation, or creating new business opportunities, web scraping Idealista can help you stay ahead of the competition.
News and updates
Stay up-to-date with the latest web scraping guides and news by subscribing to our newsletter.
We care about the protection of your data. Read our Privacy Policy.

Related articles

Learn what’s the best browser to bypass Cloudflare detection systems while web scraping with Selenium.


Learn how to use proxies with node-fetch, a popular JavaScript HTTP client, to build web scrapers. Understand how proxies work in web scraping, integrate proxies with node-fetch, and build a web scraper with proxy support.

Learn how to use Playwright for web scraping and automation with our comprehensive guide. From basic setup to advanced techniques, this guide covers it all.
